
Découverte de connaissance a partir des données
Page 1 sur 1

Découverte de connaissance a partir des données
Admin Lun 27 Juil - 15:12
Salam,
Je vais reprendre ici des notes d'un cour appelé "Découverte de connaissance à partir des données"
Ces notes de cours correspond à une partie d'un cours donné en IUP MIAG 3 année à LILE 1 et en Maitrise MASS (Math appliquée au science sociale) à Lile3
Donné par Rémi Gilleron et Marc Tommassi
Le but de ce cours et présenter des outils, des techniques liées à l'informatique décisionnelle. De l'entrepôt de données qui définit un support au système d'information décisionnel, aux outils de fouille de données permettant d'extraire de nouvelles connaissance, ces dernières sont issus de 3 grand domaine, La Statistique, L'intelligence artificielle (ensemble d'algorithmes dédié à l'apprentissage à partir des données), l'informatique (SGBD, Entrepot de donnée).
La connaissance de ce domaine est très importante voir même indispensable pour tous statisticien, quelque soit la spécialité qu'il choisis. En effet dans la plupart des formations universitaire en statistique, des modules d'informatique décisionnelle sont enseigné, voir même des spécialité entière sont dédié à ce domaine. Et vue que L'INPS n'enseigne pas ce genre de module, j'ai eut l'idée de présenter ce cours ici dans le forum, je vous demande de participer pleinement au sujet et de poser vos questions, je ferais plaisir de vos répondre.
Après la fin de ce cour inchallah, vous aurez tous pas mal de connaissance théorique, et comme c'est un domaine très intéressant vous aurez certainement envie de de pratiquer un peu le décisionnelle, ce que nous allons faire ensemble.
Programme
Introduction
1 Entrepôts de données
1.1 Informatique décisionnelle vs Informatique de Production
1.2 Construction d'un Entrepôt
1.2.1 Étude préalable
1.2.1 Modèles de données
1.2.3 Alimentation
1.3 Utilisation, exploitation
1.3.1 Requêtes
1.3.2 Agrégats et navigation.
1.3.3 Visualisation
1.3.4 Supports physique, optimisations.
2 Processus de découverte d'information
2.1 Préparation des données
2.2 Nettoyage
2.3 Enrichissement
2.4 Codage, normalisation
2.5 Fouille
2.6 Validation
3 Fouille de données
3.1 Généralités
3.2 Un algorithme pour la segmentation
3.3 Les règles d'association
3.4 Les plus proches voisins
3.5 Les arbres de décision
3.6 Les réseaux de neurones
Un programme assez riche qu'on va découvrir ensemble
Je vais reprendre ici des notes d'un cour appelé "Découverte de connaissance à partir des données"
Ces notes de cours correspond à une partie d'un cours donné en IUP MIAG 3 année à LILE 1 et en Maitrise MASS (Math appliquée au science sociale) à Lile3
Donné par Rémi Gilleron et Marc Tommassi
Le but de ce cours et présenter des outils, des techniques liées à l'informatique décisionnelle. De l'entrepôt de données qui définit un support au système d'information décisionnel, aux outils de fouille de données permettant d'extraire de nouvelles connaissance, ces dernières sont issus de 3 grand domaine, La Statistique, L'intelligence artificielle (ensemble d'algorithmes dédié à l'apprentissage à partir des données), l'informatique (SGBD, Entrepot de donnée).
La connaissance de ce domaine est très importante voir même indispensable pour tous statisticien, quelque soit la spécialité qu'il choisis. En effet dans la plupart des formations universitaire en statistique, des modules d'informatique décisionnelle sont enseigné, voir même des spécialité entière sont dédié à ce domaine. Et vue que L'INPS n'enseigne pas ce genre de module, j'ai eut l'idée de présenter ce cours ici dans le forum, je vous demande de participer pleinement au sujet et de poser vos questions, je ferais plaisir de vos répondre.
Après la fin de ce cour inchallah, vous aurez tous pas mal de connaissance théorique, et comme c'est un domaine très intéressant vous aurez certainement envie de de pratiquer un peu le décisionnelle, ce que nous allons faire ensemble.
Programme
Introduction
1 Entrepôts de données
1.1 Informatique décisionnelle vs Informatique de Production
1.2 Construction d'un Entrepôt
1.2.1 Étude préalable
1.2.1 Modèles de données
1.2.3 Alimentation
1.3 Utilisation, exploitation
1.3.1 Requêtes
1.3.2 Agrégats et navigation.
1.3.3 Visualisation
1.3.4 Supports physique, optimisations.
2 Processus de découverte d'information
2.1 Préparation des données
2.2 Nettoyage
2.3 Enrichissement
2.4 Codage, normalisation
2.5 Fouille
2.6 Validation
3 Fouille de données
3.1 Généralités
3.2 Un algorithme pour la segmentation
3.3 Les règles d'association
3.4 Les plus proches voisins
3.5 Les arbres de décision
3.6 Les réseaux de neurones
Un programme assez riche qu'on va découvrir ensemble
Dernière édition par Admin le Lun 27 Juil - 16:59, édité 1 fois

Admin- Admin
- Messages : 132
Date d'inscription : 14/11/2008
Localisation : Alger -

Re: Découverte de connaissance a partir des données
Admin Lun 27 Juil - 15:14
L'informatique de gestion a gagné sa place dans l'entreprise depuis les années 60 par une succession de progrès technologiques, logiciels et méthodologiques qui ont tous contribué à une réduction des coûts d'exploitation. L'invention du compilateur et de la compatibilité des séries de machines dans les années 60 a permis aux grands comptes de s'équiper. Le microprocesseur et les bases de données dans les années 70 ont rendu l'informatisation accessible aux moyennes et grandes entreprises. Les bases de données relationnelles, les progiciels de gestion, ainsi que les premiers micro-ordinateurs des années 80 ont largement contribué à l'équipement des petites et moyennes entreprises, commerces, administrations. Jusque là, la plus grande partie des applications était dédiée au traitement des données directement liées à l'activité quotidienne des organisations : paie, comptabilité, commandes, facturation, ...Ces applications que l'on regroupe sous le terme d'informatique de production ou Informatique Opérationnelle. L'architecture générale était l'architecture maître-esclave, avec le maître, un puissant ordinateur (mini, ou gros système) en site central et les esclaves, terminaux passifs en mode texte. L'organisation de l'entreprise était très hiérarchisée dans sa structure informatique et sa structure de pilotage. Si des techniques d'aide à la décision ont été mises en place (essentiellement basées sur des outils de simulation et d'optimisation, parfois aussi de systèmes experts), elles nécessitaient l'intervention d'équipes d'informaticiens pour le développement de produits spécifiques. Ces outils étaient mal intégrés dans le système d'information.
Avec l'apparition des ordinateurs personnels et des réseaux locaux, une autre activité a émergé, tout à fait distincte de l'informatique de production. Dans les secrétariats, les cabinets, on utilise des tableurs et des logiciels de traitements de texte, des petites bases de données sur des machines aux interfaces graphiques plus agréables. Jusqu'aux années 90, ces deux mondes (<< bureautique vs informatique >>) se sont ignorés, mais avec la montée en puissance des micro ordinateurs et l'avènement de l'architecture client-serveur, on observe aujourd'hui un décloisonnement remarquable. Le mot d'ordre principal est :
fournir à tout utilisateur reconnu et autorisé, les informations nécessaires à son travail.
Ce slogan fait naître une nouvelle informatique, intégrante, orientée vers les utilisateurs et les centres de décision des organisations. C'est l'ère du client-serveur qui prend vraiment tout son essor à la fin des années 90 avec le développement des technologies Intranet.
Enfin, un environnement de concurrence plus pressant contribue à révéler l'informatique décisionnelle. Tout utilisateur de l'entreprise ayant à prendre des décisions doit pouvoir accéder en temps réel aux données de l'entreprise, doit pouvoir traiter ces données, extraire l'information pertinente de ces données pour prendre les << bonnes >> décisions. Il se pose des questions du type : << quels sont les résultats des ventes par gamme de produit et par région pour l'année dernière ? >> ; << Quelle est l'évolution des chiffres d'affaires par type de magasin et par période >> ; ou encore << Comment qualifier les acheteurs de mon produit X ? >> ...Le système opérationnel ne peut satisfaire ces besoins pour au moins deux raisons : les bases de données opérationnelles sont trop complexes pour pouvoir être appréhendées facilement par tout utilisateur et le système opérationnel ne peut être interrompu pour répondre à des questions nécessitant des calculs importants. Il s'avère donc nécessaire de développer des systèmes d'information orientés vers la décision. Il faut garder un historique et restructurer les données de production, éventuellement récupérer des informations démographiques, géographiques et sociologiques. Les entrepôts de données ou datawarehouse sont la réalisation de ces nouveaux systèmes d'information. De nouveau, cette apparition est rendue possible grâce aux progrès technologiques à coûts constants (grâce à l'augmentation importante des capacités de stockage et à l'introduction des techniques du parallélisme dans l'informatique de gestion, techniques qui permettent des accès rapides à de grandes bases de données).
L'informatique décisionnelle s'est développée dans les années 70. Elle est alors essentiellement constituée d'outils d'édition de rapports, de statistiques, de simulation et d'optimisation. Provenant des recherches en Intelligence Artificielle, les systèmes experts apparaissent. Ils sont conçus par << extraction >> de la connaissance d'un ou plusieurs experts et sont des systèmes à base de règles. De bons résultats sont obtenus pour certains domaines d'application tels que la médecine, la géologie, la finance, ... Cependant, il apparaît vite que la formalisation sous forme de règles de la prise de décision est une tâche difficile voire impossible dans de nombreux domaines. Dans les années 90, deux phénomènes se produisent simultanément. Premièrement, comme nous l'avons montré dans les paragraphes précédents, il est possible de concevoir des environnements spécialisés pour l'aide à la décision. Deuxièmement, de nombreux algorithmes permettant d'extraire des informations à partir de données brutes sont arrivés à maturité. Ces algorithmes ont des origines diverses et souvent multiples. Certains sont issus des statistiques ; d'autres proviennent des recherches en Intelligence Artificielle, recherches qui se sont concentrées sur des projets moins ambitieux, plus ciblés ; certains s'inspirent de phénomèmes biologiques ou de la théorie de l'évolution. Tous ces algorithmes sont regroupés dans des logiciels de fouille de données ou Data Mining qui permettent la recherche d'informations nouvelles ou cachées à partir de données. Ainsi, dans le cas de systèmes à base de règles, plutôt que d'essayer d'extraire la connaissance d'experts et d'exprimer cette connaissance sous forme de règles, un logiciel va générer ces règles à partir de données. Par exemple, à partir d'un fichier historique des prêts contenant des renseignements sur les clients et le résultat du prêt (problèmes de recouvrement ou pas), le logiciel extrait un profil pour désigner un << bon >> ou un << mauvais >> client. Après validation, un tel système peut être implanté dans le système d'information de l'entreprise afin de << classer >> ou de << noter >> les nouveaux clients.
Plusieurs méthodes existent pour mettre en oeuvre la fouille de données. Le choix de l'une d'entre elles est une première difficulté pour l'utilisateur ou le concepteur. Aucune méthode n'est meilleure qu'une autre dans l'absolu. Néanmoins, l'environnement, les contraintes, les objectifs et bien sûr les propriétés des méthodes doivent guider l'utilisateur dans son choix.
Les entrepôts de données et la fouille de données sont les éléments d'un domaine de recherche et de développement très actifs actuellement : l'extraction de connaissances à partir de données ou Knowedge Discovery in Databases (KDD for short). Par ce terme, on désigne tout le cycle de découverte d'information. Il regroupe donc la conception et les accès à de grandes bases de données ; tous les traitements à effectuer pour extraire de l'information de ces données ; l'un de ces traitements est l'étape de fouille de données ou Data Mining. C'est l'objectif de ce cours que de vous en présenter les éléments essentiels.
Le plan de ce cours est le suivant :
* un premier chapitre présente les entrepôts de données (chapitre 1) en insistant sur les différences entre un tel système et les bases de données opérationnelles et transactionnelles ; en présentant des éléments méthodologiques pour la conception d'entrepôts de données, les modèles de données correspondants, les problèmes liés à l'alimentation de ces entrepôts, et quelques éléments d'information sur les technologies qui optimisent les accès à de tels systèmes.
* Un second chapitre (chapitre 2) présente le cycle complet de découverte d'informations à partir de données (Knowledge Discovery in Databases) : la préparation des données, le nettoyage, l'enrichissement, le codage et la normalisation, la fouille de données, la validation et l'intégration dans le système d'information.
* Le dernier chapitre porte une attention particulière sur la fouille de données (chapitre 3). Il est hors d'atteinte d'un tel cours de prétendre présenter toutes les techniques disponibles. Nous présentons la base des méthodes les plus classiques : l'algorithme des k-moyennes, les règles d'association, la méthode des plus proches voisins, les arbres de décision et les réseaux de neurones.
Nous recommandons essentiellement la lecture des ouvrages suivants :
* le livre de P. Adriaans et D. Zantinge [AZ96], remarquable par sa clarté, qui présente la découverte de connaissances à partir de données ;
* le livre de R. Kimball [Kim97] sur les entrepôts de données ; le livre contient de nombreux exemples ;
* le livre de M. Berry et G. Linoff [BL97] qui présente, en contexte d'applications et clairement, les méthodes de fouille de données ;
* pour ceux qui seraient plus intéressés par les aspects algorithmiques et l'apprentissage automatique, l'ouvrage de T. Mitchell [Mit97] est, en tous points, exceptionnel. Pour les aspects classification supervisée, il est possible également de consulter le poly de F. Denis et R. Gilleron [DG99] qui contient de nombreux exercices.
Avec l'apparition des ordinateurs personnels et des réseaux locaux, une autre activité a émergé, tout à fait distincte de l'informatique de production. Dans les secrétariats, les cabinets, on utilise des tableurs et des logiciels de traitements de texte, des petites bases de données sur des machines aux interfaces graphiques plus agréables. Jusqu'aux années 90, ces deux mondes (<< bureautique vs informatique >>) se sont ignorés, mais avec la montée en puissance des micro ordinateurs et l'avènement de l'architecture client-serveur, on observe aujourd'hui un décloisonnement remarquable. Le mot d'ordre principal est :
fournir à tout utilisateur reconnu et autorisé, les informations nécessaires à son travail.
Ce slogan fait naître une nouvelle informatique, intégrante, orientée vers les utilisateurs et les centres de décision des organisations. C'est l'ère du client-serveur qui prend vraiment tout son essor à la fin des années 90 avec le développement des technologies Intranet.
Enfin, un environnement de concurrence plus pressant contribue à révéler l'informatique décisionnelle. Tout utilisateur de l'entreprise ayant à prendre des décisions doit pouvoir accéder en temps réel aux données de l'entreprise, doit pouvoir traiter ces données, extraire l'information pertinente de ces données pour prendre les << bonnes >> décisions. Il se pose des questions du type : << quels sont les résultats des ventes par gamme de produit et par région pour l'année dernière ? >> ; << Quelle est l'évolution des chiffres d'affaires par type de magasin et par période >> ; ou encore << Comment qualifier les acheteurs de mon produit X ? >> ...Le système opérationnel ne peut satisfaire ces besoins pour au moins deux raisons : les bases de données opérationnelles sont trop complexes pour pouvoir être appréhendées facilement par tout utilisateur et le système opérationnel ne peut être interrompu pour répondre à des questions nécessitant des calculs importants. Il s'avère donc nécessaire de développer des systèmes d'information orientés vers la décision. Il faut garder un historique et restructurer les données de production, éventuellement récupérer des informations démographiques, géographiques et sociologiques. Les entrepôts de données ou datawarehouse sont la réalisation de ces nouveaux systèmes d'information. De nouveau, cette apparition est rendue possible grâce aux progrès technologiques à coûts constants (grâce à l'augmentation importante des capacités de stockage et à l'introduction des techniques du parallélisme dans l'informatique de gestion, techniques qui permettent des accès rapides à de grandes bases de données).
L'informatique décisionnelle s'est développée dans les années 70. Elle est alors essentiellement constituée d'outils d'édition de rapports, de statistiques, de simulation et d'optimisation. Provenant des recherches en Intelligence Artificielle, les systèmes experts apparaissent. Ils sont conçus par << extraction >> de la connaissance d'un ou plusieurs experts et sont des systèmes à base de règles. De bons résultats sont obtenus pour certains domaines d'application tels que la médecine, la géologie, la finance, ... Cependant, il apparaît vite que la formalisation sous forme de règles de la prise de décision est une tâche difficile voire impossible dans de nombreux domaines. Dans les années 90, deux phénomènes se produisent simultanément. Premièrement, comme nous l'avons montré dans les paragraphes précédents, il est possible de concevoir des environnements spécialisés pour l'aide à la décision. Deuxièmement, de nombreux algorithmes permettant d'extraire des informations à partir de données brutes sont arrivés à maturité. Ces algorithmes ont des origines diverses et souvent multiples. Certains sont issus des statistiques ; d'autres proviennent des recherches en Intelligence Artificielle, recherches qui se sont concentrées sur des projets moins ambitieux, plus ciblés ; certains s'inspirent de phénomèmes biologiques ou de la théorie de l'évolution. Tous ces algorithmes sont regroupés dans des logiciels de fouille de données ou Data Mining qui permettent la recherche d'informations nouvelles ou cachées à partir de données. Ainsi, dans le cas de systèmes à base de règles, plutôt que d'essayer d'extraire la connaissance d'experts et d'exprimer cette connaissance sous forme de règles, un logiciel va générer ces règles à partir de données. Par exemple, à partir d'un fichier historique des prêts contenant des renseignements sur les clients et le résultat du prêt (problèmes de recouvrement ou pas), le logiciel extrait un profil pour désigner un << bon >> ou un << mauvais >> client. Après validation, un tel système peut être implanté dans le système d'information de l'entreprise afin de << classer >> ou de << noter >> les nouveaux clients.
Plusieurs méthodes existent pour mettre en oeuvre la fouille de données. Le choix de l'une d'entre elles est une première difficulté pour l'utilisateur ou le concepteur. Aucune méthode n'est meilleure qu'une autre dans l'absolu. Néanmoins, l'environnement, les contraintes, les objectifs et bien sûr les propriétés des méthodes doivent guider l'utilisateur dans son choix.
Les entrepôts de données et la fouille de données sont les éléments d'un domaine de recherche et de développement très actifs actuellement : l'extraction de connaissances à partir de données ou Knowedge Discovery in Databases (KDD for short). Par ce terme, on désigne tout le cycle de découverte d'information. Il regroupe donc la conception et les accès à de grandes bases de données ; tous les traitements à effectuer pour extraire de l'information de ces données ; l'un de ces traitements est l'étape de fouille de données ou Data Mining. C'est l'objectif de ce cours que de vous en présenter les éléments essentiels.
Le plan de ce cours est le suivant :
* un premier chapitre présente les entrepôts de données (chapitre 1) en insistant sur les différences entre un tel système et les bases de données opérationnelles et transactionnelles ; en présentant des éléments méthodologiques pour la conception d'entrepôts de données, les modèles de données correspondants, les problèmes liés à l'alimentation de ces entrepôts, et quelques éléments d'information sur les technologies qui optimisent les accès à de tels systèmes.
* Un second chapitre (chapitre 2) présente le cycle complet de découverte d'informations à partir de données (Knowledge Discovery in Databases) : la préparation des données, le nettoyage, l'enrichissement, le codage et la normalisation, la fouille de données, la validation et l'intégration dans le système d'information.
* Le dernier chapitre porte une attention particulière sur la fouille de données (chapitre 3). Il est hors d'atteinte d'un tel cours de prétendre présenter toutes les techniques disponibles. Nous présentons la base des méthodes les plus classiques : l'algorithme des k-moyennes, les règles d'association, la méthode des plus proches voisins, les arbres de décision et les réseaux de neurones.
Nous recommandons essentiellement la lecture des ouvrages suivants :
* le livre de P. Adriaans et D. Zantinge [AZ96], remarquable par sa clarté, qui présente la découverte de connaissances à partir de données ;
* le livre de R. Kimball [Kim97] sur les entrepôts de données ; le livre contient de nombreux exemples ;
* le livre de M. Berry et G. Linoff [BL97] qui présente, en contexte d'applications et clairement, les méthodes de fouille de données ;
* pour ceux qui seraient plus intéressés par les aspects algorithmiques et l'apprentissage automatique, l'ouvrage de T. Mitchell [Mit97] est, en tous points, exceptionnel. Pour les aspects classification supervisée, il est possible également de consulter le poly de F. Denis et R. Gilleron [DG99] qui contient de nombreux exercices.
Admin- Admin
- Messages : 132
Date d'inscription : 14/11/2008
Localisation : Alger -
Re: Découverte de connaissance a partir des données
Admin Lun 27 Juil - 15:15
Chapitre 1 Entrepôts de données
* Informatique décisionnelle vs Informatique de production
* Construction d'un entrepôt
* Utilisation, exploitation
Un métier du secteur informatique a certainement déjà disparu : monteur de bandes. Cette personne était chargée de manutentionner des bandes magnétiques depuis les lieux de stockage jusqu'au site informatique central ou trônait un gigantesque ordinateur avec ses lecteurs de bande comme seule unité de sauvegarde. Pour charger une nouvelle application, il fallait monter la bande correspondante dans cette armoire où l'on voyait deux disques tourner, s'arrêter, changer de sens etc. Ce précieux périphérique remplaçait avantageusement les lecteurs de cartes trop lents. Mais l'apparition du disque dur, d'une remarquable capacité de 5Mo, a envoyé la bande à la décharge au milieu des années 80. Aujourd'hui, le Mo est l'unité pour la mémoire vive et nous produisons des machines stockant plusieurs PetaOctets (des millions de milliards d'octets). Ce besoin de stockage est-il justifié et en quoi est-il nécessaire ?
Les sociétés de téléphone gardent au moins un an les positions géographiques et les consommations de leurs abonnés << mobiles >>. Les grands magasins et les entreprises de vente par correspondance (VPC) conservent les achats de leurs clients (tickets de caisse en grande distribution, commandes en VPC), collectent des informations sur leurs clients grâce à des systèmes de cartes de fidélité ou de crédit, et achètent des bases de données géographiques et démographiques. Les sites web conservent des traces de connexions sur leurs sites marchands. En résumé, les entreprises en secteur très concurrentiel conservent les données de leur activité et achètent même des données.
Les motifs qui ont présidé à la conservation de ces données étaient : des obligations légales pour pouvoir justifier les facturations, des raisons de sécurité pour pouvoir détecter les fraudes, des motifs commerciaux pour suivre l'évolution des clients et des marchés. Quelle que soit la raison initiale, les entreprises se sont rendues compte que ces données pouvaient être une source d'informations à leur service. Ce constat, valable pour les sociétés du secteur marchand, peut être étendu à de nombreux domaines comme la médecine, la pharmacologie. Il faut donc définir des environnements permettant de mémoriser de grands jeux de données et d'en extraire de l'information.
Les structures qui accueillent ce flot important de données sont des entrepôts de données ou data warehouse. Ils sont construits sur une nouvelle architecture permettant d'extraire l'information, architecture bien différente de celle prévue pour l'informatique de production, basée elle sur des systèmes de gestion de bases de données relationnelles et des serveurs transactionnels. Un entrepôt de données est construit en l'alimentant via les serveurs transactionnels de façon bien choisie et réfléchie pour permettre aux procédures d'extraction de connaissances de bien fonctionner. L'organisation logique des données est particulièrement conçue pour autoriser des recherches complexes. Le matériel est évidemment adapté à cette utilisation.
Nous rappelons les différences essentielles entre informatique de production et de décision (section 1.1). La phase de construction est abordée en section 1.2. Nous la présentons en trois parties : l'étude préalable qui étudie la faisabilité, les besoins ; l'étude des données et de leur modélisation ; l'étude de l'alimentation l'entrepôt. Le chapitre se termine par une présentation rapide des outils d'exploitation et d'administration : navigation, optimisation, requêtes et visualisation (section 1.3).
* Informatique décisionnelle vs Informatique de production
* Construction d'un entrepôt
* Utilisation, exploitation
Un métier du secteur informatique a certainement déjà disparu : monteur de bandes. Cette personne était chargée de manutentionner des bandes magnétiques depuis les lieux de stockage jusqu'au site informatique central ou trônait un gigantesque ordinateur avec ses lecteurs de bande comme seule unité de sauvegarde. Pour charger une nouvelle application, il fallait monter la bande correspondante dans cette armoire où l'on voyait deux disques tourner, s'arrêter, changer de sens etc. Ce précieux périphérique remplaçait avantageusement les lecteurs de cartes trop lents. Mais l'apparition du disque dur, d'une remarquable capacité de 5Mo, a envoyé la bande à la décharge au milieu des années 80. Aujourd'hui, le Mo est l'unité pour la mémoire vive et nous produisons des machines stockant plusieurs PetaOctets (des millions de milliards d'octets). Ce besoin de stockage est-il justifié et en quoi est-il nécessaire ?
Les sociétés de téléphone gardent au moins un an les positions géographiques et les consommations de leurs abonnés << mobiles >>. Les grands magasins et les entreprises de vente par correspondance (VPC) conservent les achats de leurs clients (tickets de caisse en grande distribution, commandes en VPC), collectent des informations sur leurs clients grâce à des systèmes de cartes de fidélité ou de crédit, et achètent des bases de données géographiques et démographiques. Les sites web conservent des traces de connexions sur leurs sites marchands. En résumé, les entreprises en secteur très concurrentiel conservent les données de leur activité et achètent même des données.
Les motifs qui ont présidé à la conservation de ces données étaient : des obligations légales pour pouvoir justifier les facturations, des raisons de sécurité pour pouvoir détecter les fraudes, des motifs commerciaux pour suivre l'évolution des clients et des marchés. Quelle que soit la raison initiale, les entreprises se sont rendues compte que ces données pouvaient être une source d'informations à leur service. Ce constat, valable pour les sociétés du secteur marchand, peut être étendu à de nombreux domaines comme la médecine, la pharmacologie. Il faut donc définir des environnements permettant de mémoriser de grands jeux de données et d'en extraire de l'information.
Les structures qui accueillent ce flot important de données sont des entrepôts de données ou data warehouse. Ils sont construits sur une nouvelle architecture permettant d'extraire l'information, architecture bien différente de celle prévue pour l'informatique de production, basée elle sur des systèmes de gestion de bases de données relationnelles et des serveurs transactionnels. Un entrepôt de données est construit en l'alimentant via les serveurs transactionnels de façon bien choisie et réfléchie pour permettre aux procédures d'extraction de connaissances de bien fonctionner. L'organisation logique des données est particulièrement conçue pour autoriser des recherches complexes. Le matériel est évidemment adapté à cette utilisation.
Nous rappelons les différences essentielles entre informatique de production et de décision (section 1.1). La phase de construction est abordée en section 1.2. Nous la présentons en trois parties : l'étude préalable qui étudie la faisabilité, les besoins ; l'étude des données et de leur modélisation ; l'étude de l'alimentation l'entrepôt. Le chapitre se termine par une présentation rapide des outils d'exploitation et d'administration : navigation, optimisation, requêtes et visualisation (section 1.3).
Admin- Admin
- Messages : 132
Date d'inscription : 14/11/2008
Localisation : Alger -
Re: Découverte de connaissance a partir des données
Admin Lun 27 Juil - 15:16
1.1 Informatique décisionnelle vs Informatique de production
Une des principales caractéristiques des systèmes de production est une activité constante constituée de modifications et d'interrogations fréquentes des données par de nombreux utilisateurs : ajouter une commande, modifier une adresse de livraison, rechercher les coordonnées d'un client, ... Il faut conserver la cohérence des données (il faut interdire la modification simultanée d'une même donnée par deux utilisateurs différents). Il s'agit donc de privilégier un enregistrement rapide et sûr des données. À l'inverse, les utilisateurs des systèmes d'information de décision n'ont aucun besoin de modification ou d'enregistrement de nouvelles données. Ils vont interroger le système d'information et les questions posées seront de la forme : << quelles sont les ventes du produit X pendant le trimestre A de l'année B dans la région C >>. Une telle interrogation peut nécessiter des temps de calcul importants. Or, l'activité d'un serveur transactionnel ne peut être interrompue. Il faut donc prévoir une nouvelle organisation qui permette de mémoriser de grands jeux de données et qui facilite la recherche d'informations.
Enfin, nous étudierons dans le chapitre suivant l'extraction de connaissances à partir de données. Les méthodes de fouille de données nécessitent une préparation et une organisation particulière des données que nous détaillerons au chapitre suivant. L'existence d'un entrepôt simplifiera cette tâche et permettra donc d'optimiser le temps de développement d'un projet d'extraction de connaissances. En résumé, on peut justifier la construction d'un entrepôt de données par l'affirmation suivante :
il est beaucoup plus simple de trouver une information pertinente dans une structure organisée pour la recherche de connaissance.
La production
Le modèle Entité-Association (ou modèle EA) est l'un des formalismes les plus utilisés pour la représentation conceptuelle des systèmes d'information. Il permet de construire des modèles de données dans lesquels on cherche à tout prix à éviter des redondances. Toute donnée mémorisée plus d'une fois est source d'erreurs, d'incohérences, et va pénaliser les temps d'exécution et complexifier les procédures d'ajout, de suppression ou de modification.
D'un point de vue logique, ce sont les bases de données relationnelles qui ont su au mieux représenter ces modèles conceptuels. Les éditeurs de logiciels et les architectes d'ordinateurs ont dû fournir un effort important pour les rendre efficaces. Aujourd'hui les bases relationnelles ont acquis une maturité satisfaisante pour être largement utilisées et diffusées dans de nombreuses organisations, à toute échelle.
Conserver la cohérence de la base de données, c'est l'objectif et la difficulté principale pour l'informatique de production. Les systèmes transactionnels (temps réel) OLTP (On-Line Transaction Processing) garantissent l'intégrité des données. Les utilisateurs accèdent à des éléments de la base par de très courtes transactions indécomposables, isolées. Ils y accèdent très souvent pour des opérations d'ajout, suppression, modification mais aussi de lecture. L'isolation permet de garantir que la transaction ne sera pas perturbée ni interrompue. Les contrôles effectués sont élémentaires. La brièveté garantit que les temps de réponse seront acceptables (inférieurs à la seconde) dans un environnement avec de nombreux utilisateurs.
Bien sûr, dans le souci de la garantie des performances, une requête dont le calcul prendrait trop de temps est inacceptable. Par exemple, une jointure sur de grosses tables à l'aide de champs non indexés est interdite. Les travaux sur une telle base sont souvent simples et répétitifs. Dès lors qu'un travail plus important est nécessaire, l'intervention de programmeurs et d'administrateurs de la base est requise et une procédure ad-hoc est créée et optimisée.
Le modèle Entité-Association et sa réalisation dans un schéma relationnel sont pourtant des obstacles importants pour l'accès de l'utilisateur final aux données. Dans une situation réelle, le modèle des données est très large et contient plusieurs dizaines d'entités. Les bases sont alors constituées de nombreuses tables, reliées entre elles par divers liens dont le sens n'est pas toujours explicite. Souvent, les organisations ont choisi une norme pour définir des noms à chaque objet (table, champ,...) très << syntaxiques >> sans sémantique claire. Le but était de faciliter le travail des développeurs et l'efficacité des procédures. L'utilisateur final n'est pas considéré ici car c'est à l'informaticien de lui proposer une abstraction de ces modèles à travers les outils dont il a besoin. La complexité des données, l'absence d'annuaire clair rend la base inutilisable aux non initiés sans l'intervention d'informaticiens et d'outils sur mesure.
L'informatique de production a donc été conçue pour privilégier les performances de tâches répétitives, prévues et planifiées tournées vers la production de documents standards (factures, commandes...). L'intervention de l'utilisateur est guidée à travers des outils spécifiques proposés par une équipe de développeurs.
La dernière caractéristique de ces bases de données est qu'elles conservent l'état instantané du système. Dans la plupart des cas, l'évolution n'est pas conservée. On conserve simplement des versions instantanées pour la reprise en cas de panne et pour des raisons légales.
Le décisionnel
Dans un système d'information décisionnel, l'utilisateur final formulera des questions du type :
* Comment se comporte le produit X par rapport au produit Y ?
* Et par rapport à l'année dernière ?
* Quel type de client peut bien acheter mon produit Z ?
Ces exemples permettent de mettre en évidence les faits suivants :
* les questions doivent pouvoir être formulées dans le langage de l'utilisateur en fonction de son << métier >>, c'est-à-dire de son secteur d'activité (service marketing, service économique, service gestion des ressources humaines, ...) ;
* la prévision des interrogations est difficile car elles sont du ressort de l'utilisateur. De plus, ses questions vont varier selon les réponses obtenues : : si le produit X s'est vendu moins bien que l'année précédente, il va être utile d'en comprendre les raisons et donc de détailler les ventes du produit X (par région, par type de magasin, ...)
* des questions ouvertes (profil client du produit Z) vont nécessiter la mise en place de méthodes d'extraction d'informations.
Ce qui caractérise d'abord les besoins, c'est donc la possibilité de poser une grande variété de questions au système, certaines prévisibles et planifiées comme des tableaux de bord et d'autres imprévisibles. Si des outils d'édition automatiques pré-programmés peuvent être envisagés, il est nécessaire de permettre à l'utilisateur d'effectuer les requêtes qu'il souhaite, par lui-même, sans intervention de programmeurs. Deux contraintes apparaissent alors immédiatement: la simplicité du modèle des données, la performance malgré les grands volumes.
Pour les entrepôts de données, on recherche plus de lisibilité, de simplicité que dans le cas des SGBD. La modélisation introduit les notions de fait et dimension. Les faits correspondent à l'activité de l'entreprise : ce sont les ventes pour une entreprise commerciale, les communications pour une entreprise de télécommunications, ... Les dimensions sont les critères sur lesquels on souhaite évaluer, quantifier, qualifier les faits : les dimensions usuelles sont le temps, le client, le magasin, la région, le produit...
Dans les exemples de requêtes citées au début de ce paragraphe, les faits et les dimensions apparaissent :
* les ventes en fait ;
* les produits, les clients, le temps, le lieu en dimensions.
Il sera souvent nécessaire de filtrer, d'agréger, de compter, sommer et de réaliser quelques statistiques élémentaires (moyenne, écart-type,...). La structure logique doit être prévue pour rendre aussi efficace que possible toutes ces requêtes. Pour y parvenir, on est amené à introduire de la redondance dans les informations stockées en mémorisant des calculs intermédiaires (dans l'exemple, on peut être amené à stocker toutes les sommes de ventes par produit ou par année). On rompt donc avec le principe de non redondance des bases de production.
Si le critère de cohérence semble assuré avec les techniques du transactionnel, cette cohérence est toute relative. Elle se contrôle au niveau de la transaction élémentaire mais pas au niveau global et des activités de l'organisation. Pour les entrepôts, on requiert une cohérence interprétable par l'utilisateur. Par exemple, si les livraisons n'ont pas été toutes saisies dans le système, comment garantir la cohérence de l'état du stock ? Autre, exemple, pour établir un profil client ou étudier les performances d'un magasin, toutes les données utiles le concernant doivent être présentes dans le système, ce que n'assure pas le serveur transactionnel mais que doit assurer le serveur décisionnel.
Les entrepôts de données assureront donc plutôt une cohérence globale des données. Pour cette raison, leur alimentation sera un acte réfléchi et planifié dans le temps. Un grand nombre d'informations sera importé du système transactionnel lorsqu'on aura la garantie que toutes les données nécessaires auront été produites et mémorisées. Les transferts de données du système opérationnel vers le système décisionnel seront réguliers avec une périodicité bien choisie dépendante de l'activité de l'entreprise. Chaque transfert sera contrôlé avant d'être diffusé.
Une dernière caractéristique importante des entrepôts, qui est aussi une différence fondamentale avec les bases de production, est qu'aucune information n'y est jamais modifiée. En effet, on mémorise toutes les données sur une période donnée et terminée, il n'y aura donc jamais à remettre en cause ces données car toutes les vérifications utiles auront été faites lors de l'alimentation. L'utilisation se résume donc à un chargement périodique, puis à des interrogations non régulières, non prévisibles, parfois longues à exécuter.
Une des principales caractéristiques des systèmes de production est une activité constante constituée de modifications et d'interrogations fréquentes des données par de nombreux utilisateurs : ajouter une commande, modifier une adresse de livraison, rechercher les coordonnées d'un client, ... Il faut conserver la cohérence des données (il faut interdire la modification simultanée d'une même donnée par deux utilisateurs différents). Il s'agit donc de privilégier un enregistrement rapide et sûr des données. À l'inverse, les utilisateurs des systèmes d'information de décision n'ont aucun besoin de modification ou d'enregistrement de nouvelles données. Ils vont interroger le système d'information et les questions posées seront de la forme : << quelles sont les ventes du produit X pendant le trimestre A de l'année B dans la région C >>. Une telle interrogation peut nécessiter des temps de calcul importants. Or, l'activité d'un serveur transactionnel ne peut être interrompue. Il faut donc prévoir une nouvelle organisation qui permette de mémoriser de grands jeux de données et qui facilite la recherche d'informations.
Enfin, nous étudierons dans le chapitre suivant l'extraction de connaissances à partir de données. Les méthodes de fouille de données nécessitent une préparation et une organisation particulière des données que nous détaillerons au chapitre suivant. L'existence d'un entrepôt simplifiera cette tâche et permettra donc d'optimiser le temps de développement d'un projet d'extraction de connaissances. En résumé, on peut justifier la construction d'un entrepôt de données par l'affirmation suivante :
il est beaucoup plus simple de trouver une information pertinente dans une structure organisée pour la recherche de connaissance.
La production
Le modèle Entité-Association (ou modèle EA) est l'un des formalismes les plus utilisés pour la représentation conceptuelle des systèmes d'information. Il permet de construire des modèles de données dans lesquels on cherche à tout prix à éviter des redondances. Toute donnée mémorisée plus d'une fois est source d'erreurs, d'incohérences, et va pénaliser les temps d'exécution et complexifier les procédures d'ajout, de suppression ou de modification.
D'un point de vue logique, ce sont les bases de données relationnelles qui ont su au mieux représenter ces modèles conceptuels. Les éditeurs de logiciels et les architectes d'ordinateurs ont dû fournir un effort important pour les rendre efficaces. Aujourd'hui les bases relationnelles ont acquis une maturité satisfaisante pour être largement utilisées et diffusées dans de nombreuses organisations, à toute échelle.
Conserver la cohérence de la base de données, c'est l'objectif et la difficulté principale pour l'informatique de production. Les systèmes transactionnels (temps réel) OLTP (On-Line Transaction Processing) garantissent l'intégrité des données. Les utilisateurs accèdent à des éléments de la base par de très courtes transactions indécomposables, isolées. Ils y accèdent très souvent pour des opérations d'ajout, suppression, modification mais aussi de lecture. L'isolation permet de garantir que la transaction ne sera pas perturbée ni interrompue. Les contrôles effectués sont élémentaires. La brièveté garantit que les temps de réponse seront acceptables (inférieurs à la seconde) dans un environnement avec de nombreux utilisateurs.
Bien sûr, dans le souci de la garantie des performances, une requête dont le calcul prendrait trop de temps est inacceptable. Par exemple, une jointure sur de grosses tables à l'aide de champs non indexés est interdite. Les travaux sur une telle base sont souvent simples et répétitifs. Dès lors qu'un travail plus important est nécessaire, l'intervention de programmeurs et d'administrateurs de la base est requise et une procédure ad-hoc est créée et optimisée.
Le modèle Entité-Association et sa réalisation dans un schéma relationnel sont pourtant des obstacles importants pour l'accès de l'utilisateur final aux données. Dans une situation réelle, le modèle des données est très large et contient plusieurs dizaines d'entités. Les bases sont alors constituées de nombreuses tables, reliées entre elles par divers liens dont le sens n'est pas toujours explicite. Souvent, les organisations ont choisi une norme pour définir des noms à chaque objet (table, champ,...) très << syntaxiques >> sans sémantique claire. Le but était de faciliter le travail des développeurs et l'efficacité des procédures. L'utilisateur final n'est pas considéré ici car c'est à l'informaticien de lui proposer une abstraction de ces modèles à travers les outils dont il a besoin. La complexité des données, l'absence d'annuaire clair rend la base inutilisable aux non initiés sans l'intervention d'informaticiens et d'outils sur mesure.
L'informatique de production a donc été conçue pour privilégier les performances de tâches répétitives, prévues et planifiées tournées vers la production de documents standards (factures, commandes...). L'intervention de l'utilisateur est guidée à travers des outils spécifiques proposés par une équipe de développeurs.
La dernière caractéristique de ces bases de données est qu'elles conservent l'état instantané du système. Dans la plupart des cas, l'évolution n'est pas conservée. On conserve simplement des versions instantanées pour la reprise en cas de panne et pour des raisons légales.
Le décisionnel
Dans un système d'information décisionnel, l'utilisateur final formulera des questions du type :
* Comment se comporte le produit X par rapport au produit Y ?
* Et par rapport à l'année dernière ?
* Quel type de client peut bien acheter mon produit Z ?
Ces exemples permettent de mettre en évidence les faits suivants :
* les questions doivent pouvoir être formulées dans le langage de l'utilisateur en fonction de son << métier >>, c'est-à-dire de son secteur d'activité (service marketing, service économique, service gestion des ressources humaines, ...) ;
* la prévision des interrogations est difficile car elles sont du ressort de l'utilisateur. De plus, ses questions vont varier selon les réponses obtenues : : si le produit X s'est vendu moins bien que l'année précédente, il va être utile d'en comprendre les raisons et donc de détailler les ventes du produit X (par région, par type de magasin, ...)
* des questions ouvertes (profil client du produit Z) vont nécessiter la mise en place de méthodes d'extraction d'informations.
Ce qui caractérise d'abord les besoins, c'est donc la possibilité de poser une grande variété de questions au système, certaines prévisibles et planifiées comme des tableaux de bord et d'autres imprévisibles. Si des outils d'édition automatiques pré-programmés peuvent être envisagés, il est nécessaire de permettre à l'utilisateur d'effectuer les requêtes qu'il souhaite, par lui-même, sans intervention de programmeurs. Deux contraintes apparaissent alors immédiatement: la simplicité du modèle des données, la performance malgré les grands volumes.
Pour les entrepôts de données, on recherche plus de lisibilité, de simplicité que dans le cas des SGBD. La modélisation introduit les notions de fait et dimension. Les faits correspondent à l'activité de l'entreprise : ce sont les ventes pour une entreprise commerciale, les communications pour une entreprise de télécommunications, ... Les dimensions sont les critères sur lesquels on souhaite évaluer, quantifier, qualifier les faits : les dimensions usuelles sont le temps, le client, le magasin, la région, le produit...
Dans les exemples de requêtes citées au début de ce paragraphe, les faits et les dimensions apparaissent :
* les ventes en fait ;
* les produits, les clients, le temps, le lieu en dimensions.
Il sera souvent nécessaire de filtrer, d'agréger, de compter, sommer et de réaliser quelques statistiques élémentaires (moyenne, écart-type,...). La structure logique doit être prévue pour rendre aussi efficace que possible toutes ces requêtes. Pour y parvenir, on est amené à introduire de la redondance dans les informations stockées en mémorisant des calculs intermédiaires (dans l'exemple, on peut être amené à stocker toutes les sommes de ventes par produit ou par année). On rompt donc avec le principe de non redondance des bases de production.
Si le critère de cohérence semble assuré avec les techniques du transactionnel, cette cohérence est toute relative. Elle se contrôle au niveau de la transaction élémentaire mais pas au niveau global et des activités de l'organisation. Pour les entrepôts, on requiert une cohérence interprétable par l'utilisateur. Par exemple, si les livraisons n'ont pas été toutes saisies dans le système, comment garantir la cohérence de l'état du stock ? Autre, exemple, pour établir un profil client ou étudier les performances d'un magasin, toutes les données utiles le concernant doivent être présentes dans le système, ce que n'assure pas le serveur transactionnel mais que doit assurer le serveur décisionnel.
Les entrepôts de données assureront donc plutôt une cohérence globale des données. Pour cette raison, leur alimentation sera un acte réfléchi et planifié dans le temps. Un grand nombre d'informations sera importé du système transactionnel lorsqu'on aura la garantie que toutes les données nécessaires auront été produites et mémorisées. Les transferts de données du système opérationnel vers le système décisionnel seront réguliers avec une périodicité bien choisie dépendante de l'activité de l'entreprise. Chaque transfert sera contrôlé avant d'être diffusé.
Une dernière caractéristique importante des entrepôts, qui est aussi une différence fondamentale avec les bases de production, est qu'aucune information n'y est jamais modifiée. En effet, on mémorise toutes les données sur une période donnée et terminée, il n'y aura donc jamais à remettre en cause ces données car toutes les vérifications utiles auront été faites lors de l'alimentation. L'utilisation se résume donc à un chargement périodique, puis à des interrogations non régulières, non prévisibles, parfois longues à exécuter.
Admin- Admin
- Messages : 132
Date d'inscription : 14/11/2008
Localisation : Alger -
Re: Découverte de connaissance a partir des données
Admin Lun 27 Juil - 15:17
1.2 Construction d'un entrepôt
L'entrepôt de données est donc bien différent des bases de données de production car les besoins pour lesquels on veut le construire sont différents. Il contient des informations historisées, globalement cohérentes, organisées selon les métiers de l'entreprise pour le processus de décision. L'entrepôt n'est pas un produit ou un logiciel mais un environnement. Il se bâtit et ne s'achète pas. Les données sont puisées dans les bases de production, nettoyées, normalisées, puis intégrées. Des métadonnées décrivent les informations dans cette nouvelle base pour lever toute ambiguïté quant à leur origine et leur signification.
Nous décrivons, dans ce chapitre, les problèmes liés à la construction d'un entrepôt, les modèles de données et son alimentation. Mais, il faut garder à l'esprit qu'un entrepôt se conçoit avec un ensemble d'applications qui vont réaliser ce pour quoi il a été construit : l'aide à la décision. Ce sont des outils d'accès aux données (requêteurs, visualisateurs, outils de fouille, ...) qui seront plus précisément décrits dans la suite de ce cours.
Nous avons relevé trois parties interdépendantes qui relèvent de la construction d'un entrepôt de données :
1. L'étude préalable qui va poser la question du retour sur investissement, définir les objectifs, préciser la démarche.
2. L'étude du modèle des données qui représente l'entrepôt conceptuellement et logiquement.
3. L'étude de l'alimentation qui reprend à un niveau plus précis l'examen des données, le choix des méthodes et des dates auxquelles les données entreront dans l'entrepôt.
Nous terminons par quelques remarques sur les machines dédiées aux entrepôts de données et les optimisations à mettre en oeuvre pour assurer de bons temps de réponse.
1.2.1 Étude préalable
Cette partie de l'étude ressemble à toute étape préliminaire à l'implantation d'un nouveau système d'information automatisé. Les principes des méthodes connues pour le système de production restent valables ici.
Étude des besoins
L'étude des besoins doit déterminer le contenu de l'entrepôt et son organisation, d'après les résultats attendus par les utilisateurs, les requêtes qu'ils formuleront, les projets qui ont été définis. Le besoin d'informatisation peut provenir du système de pilotage ou d'un service particulier de l'entreprise. C'est souvent un projet au sein d'un schéma directeur qui va déclencher l'étude et la réalisation d'un cahier des charges. L'existant dans ce domaine est généralement un ensemble de petits produits ou développements sans grande intégration ni relations, disséminés dans divers services. L'information est dupliquée, les traitements répétés et aucune stratégie d'ensemble n'est définie. Le projet va donc s'orienter vers la recherche d'une solution intégrante résolument tournée vers l'utilisateur.
L'expression des besoins par les utilisateurs met souvent en évidence la volonté d'obtenir : des analyses sur ce qui s'est passé (par exemple comparer les performances actuelles d'un magasin avec celles de l'année dernière) ou des analyses prédictives (par exemple déterminer les achats potentiels pour un type de client, déterminer les clients qui risquent d'abandonner l'entreprise, ...).
Les interviews doivent permettre de préciser les faits à suivre et dans quelles dimensions. Il faut recenser les données nécessaires à un bon fonctionnement de l'entrepôt. Il faut alors recenser les données disponibles dans les bases de production, toutes les données de production ne sont pas utiles dans l'entrepôt. Il faut aussi identifier les données supplémentaires requises et s'assurer la possibilité de se les procurer (achat de bases géographiques, démographiques, ...).
L'examen des dimensions dans lesquelles les faits seront suivis doit donner lieu à une étude de l'unité de ces dimensions, de la granularité de ces faits. Par exemple, l'unité de temps doit-elle être le jour, la semaine ? Les produits sont-ils analysés par catégorie, par lot, par marque ?
La variété des besoins, leur modularité peut entraîner un découpage de l'entrepôt en plusieurs parties : les datamart. Les datamart sont alimentés par un entrepôt et sont dédiés à une activité particulière pour un ou plusieurs services (le suivi des clients, la prévision des stocks). On peut mener l'analyse soit de façon ascendante (en commençant par les datamart), soit de manière descendante.
Le lecteur intéressé est encouragé à consulter les neuf règles pour la conception d'entrepôts de données proposées par Ralf Kimball ([Kim97]).
Coûts de déploiement
Il faut une machine puissante, souvent une machine parallèle, spécialisée pour cette tâche. Les tentatives de mixer à la fois l'informatique de décision et l'informatique de production au sein d'une seule machine sont souvent des échecs. Comme nous l'avons vu précédemment les utilisations sont trop différentes. La capacité de stockage doit être très importante. Les prévisions de montée en charge du système devront évaluer cette quantité. Il faut noter que les prix de ces matériels ne cessent de décroître. En vertu de la loi de Moore, la puissance de stockage (resp. de calcul) est multipliée par deux tous les 2 ans (resp. 18 mois) et cette tendance s'accélère même, à prix constant.
Comme tout système informatique, il faut une équipe pour le maintenir, le faire évoluer (administrateur, développeurs, concepteurs,...). Il faut prévoir la mise en place, la formation, etc.
Les coûts logiciels peuvent être importants. Ils concernent les logiciels d'administration de l'entrepôt, des logiciels d'interrogation et de visualisation ainsi que les coûts de l'environnement logiciel de data mining proprement dit. L'entrepôt devra être accessible par tout utilisateur et on se situe, généralement, dans un environnement client-serveur.
Bénéfices attendus
Nous verrons, au chapitre suivant, qu'il est possible de développer un projet d'extraction de connaissances à partir de données sans mise en place d'un entrepôt de données. Cependant, par définition de l'entrepôt, les données ont été préparées et le travail sera donc facilité.
Il est possible de calculer les espérances de gain en prévoyant les performances du système. Il faut, pour cela, effectuer une étude exhaustive des services de l'entreprise demandeurs d'un environnement d'aide à la décision à partir de données. Pour chacun des services, il faut recenser des projets sur lesquels des bénéfices peuvent être retirés d'une telle implantation. Pour chacun des projets, il faut alors estimer les bénéfices attendus.
Prenons l'exemple du service marketing direct qui veut augmenter le taux de réponse aux courriers qu'elle envoie. À l'aide d'un entrepôt de données, elle va mémoriser son activité et tenter d'établir des profils dans sa clientèle. Si un outil de fouille de données permet de prédire avec un certain taux d'erreur si un client répondra ou non au courrier, la société peut cibler son action. Avec des mailings maintenant ciblés, elle peut réduire le nombre d'envois tout en conservant le même nombre de retours. L'économie peut alors être quantifiée et comparée aux coûts d'investissement.
Il est important de noter que, au vu des investissements nécessaires, il est fréquent de commencer par le développement de serveurs départementaux pour l'entrepôt (Datamart) sur des projets clairement définis avant de passer à une généralisation à l'ensemble des services de l'entreprise.
L'étude préalable se conclue par la rédaction d'un cahier des charges comprenant la solution envisagée, le bilan du retour sur investissement et la décision d'implantation.
L'entrepôt de données est donc bien différent des bases de données de production car les besoins pour lesquels on veut le construire sont différents. Il contient des informations historisées, globalement cohérentes, organisées selon les métiers de l'entreprise pour le processus de décision. L'entrepôt n'est pas un produit ou un logiciel mais un environnement. Il se bâtit et ne s'achète pas. Les données sont puisées dans les bases de production, nettoyées, normalisées, puis intégrées. Des métadonnées décrivent les informations dans cette nouvelle base pour lever toute ambiguïté quant à leur origine et leur signification.
Nous décrivons, dans ce chapitre, les problèmes liés à la construction d'un entrepôt, les modèles de données et son alimentation. Mais, il faut garder à l'esprit qu'un entrepôt se conçoit avec un ensemble d'applications qui vont réaliser ce pour quoi il a été construit : l'aide à la décision. Ce sont des outils d'accès aux données (requêteurs, visualisateurs, outils de fouille, ...) qui seront plus précisément décrits dans la suite de ce cours.
Nous avons relevé trois parties interdépendantes qui relèvent de la construction d'un entrepôt de données :
1. L'étude préalable qui va poser la question du retour sur investissement, définir les objectifs, préciser la démarche.
2. L'étude du modèle des données qui représente l'entrepôt conceptuellement et logiquement.
3. L'étude de l'alimentation qui reprend à un niveau plus précis l'examen des données, le choix des méthodes et des dates auxquelles les données entreront dans l'entrepôt.
Nous terminons par quelques remarques sur les machines dédiées aux entrepôts de données et les optimisations à mettre en oeuvre pour assurer de bons temps de réponse.
1.2.1 Étude préalable
Cette partie de l'étude ressemble à toute étape préliminaire à l'implantation d'un nouveau système d'information automatisé. Les principes des méthodes connues pour le système de production restent valables ici.
Étude des besoins
L'étude des besoins doit déterminer le contenu de l'entrepôt et son organisation, d'après les résultats attendus par les utilisateurs, les requêtes qu'ils formuleront, les projets qui ont été définis. Le besoin d'informatisation peut provenir du système de pilotage ou d'un service particulier de l'entreprise. C'est souvent un projet au sein d'un schéma directeur qui va déclencher l'étude et la réalisation d'un cahier des charges. L'existant dans ce domaine est généralement un ensemble de petits produits ou développements sans grande intégration ni relations, disséminés dans divers services. L'information est dupliquée, les traitements répétés et aucune stratégie d'ensemble n'est définie. Le projet va donc s'orienter vers la recherche d'une solution intégrante résolument tournée vers l'utilisateur.
L'expression des besoins par les utilisateurs met souvent en évidence la volonté d'obtenir : des analyses sur ce qui s'est passé (par exemple comparer les performances actuelles d'un magasin avec celles de l'année dernière) ou des analyses prédictives (par exemple déterminer les achats potentiels pour un type de client, déterminer les clients qui risquent d'abandonner l'entreprise, ...).
Les interviews doivent permettre de préciser les faits à suivre et dans quelles dimensions. Il faut recenser les données nécessaires à un bon fonctionnement de l'entrepôt. Il faut alors recenser les données disponibles dans les bases de production, toutes les données de production ne sont pas utiles dans l'entrepôt. Il faut aussi identifier les données supplémentaires requises et s'assurer la possibilité de se les procurer (achat de bases géographiques, démographiques, ...).
L'examen des dimensions dans lesquelles les faits seront suivis doit donner lieu à une étude de l'unité de ces dimensions, de la granularité de ces faits. Par exemple, l'unité de temps doit-elle être le jour, la semaine ? Les produits sont-ils analysés par catégorie, par lot, par marque ?
La variété des besoins, leur modularité peut entraîner un découpage de l'entrepôt en plusieurs parties : les datamart. Les datamart sont alimentés par un entrepôt et sont dédiés à une activité particulière pour un ou plusieurs services (le suivi des clients, la prévision des stocks). On peut mener l'analyse soit de façon ascendante (en commençant par les datamart), soit de manière descendante.
Le lecteur intéressé est encouragé à consulter les neuf règles pour la conception d'entrepôts de données proposées par Ralf Kimball ([Kim97]).
Coûts de déploiement
Il faut une machine puissante, souvent une machine parallèle, spécialisée pour cette tâche. Les tentatives de mixer à la fois l'informatique de décision et l'informatique de production au sein d'une seule machine sont souvent des échecs. Comme nous l'avons vu précédemment les utilisations sont trop différentes. La capacité de stockage doit être très importante. Les prévisions de montée en charge du système devront évaluer cette quantité. Il faut noter que les prix de ces matériels ne cessent de décroître. En vertu de la loi de Moore, la puissance de stockage (resp. de calcul) est multipliée par deux tous les 2 ans (resp. 18 mois) et cette tendance s'accélère même, à prix constant.
Comme tout système informatique, il faut une équipe pour le maintenir, le faire évoluer (administrateur, développeurs, concepteurs,...). Il faut prévoir la mise en place, la formation, etc.
Les coûts logiciels peuvent être importants. Ils concernent les logiciels d'administration de l'entrepôt, des logiciels d'interrogation et de visualisation ainsi que les coûts de l'environnement logiciel de data mining proprement dit. L'entrepôt devra être accessible par tout utilisateur et on se situe, généralement, dans un environnement client-serveur.
Bénéfices attendus
Nous verrons, au chapitre suivant, qu'il est possible de développer un projet d'extraction de connaissances à partir de données sans mise en place d'un entrepôt de données. Cependant, par définition de l'entrepôt, les données ont été préparées et le travail sera donc facilité.
Il est possible de calculer les espérances de gain en prévoyant les performances du système. Il faut, pour cela, effectuer une étude exhaustive des services de l'entreprise demandeurs d'un environnement d'aide à la décision à partir de données. Pour chacun des services, il faut recenser des projets sur lesquels des bénéfices peuvent être retirés d'une telle implantation. Pour chacun des projets, il faut alors estimer les bénéfices attendus.
Prenons l'exemple du service marketing direct qui veut augmenter le taux de réponse aux courriers qu'elle envoie. À l'aide d'un entrepôt de données, elle va mémoriser son activité et tenter d'établir des profils dans sa clientèle. Si un outil de fouille de données permet de prédire avec un certain taux d'erreur si un client répondra ou non au courrier, la société peut cibler son action. Avec des mailings maintenant ciblés, elle peut réduire le nombre d'envois tout en conservant le même nombre de retours. L'économie peut alors être quantifiée et comparée aux coûts d'investissement.
Il est important de noter que, au vu des investissements nécessaires, il est fréquent de commencer par le développement de serveurs départementaux pour l'entrepôt (Datamart) sur des projets clairement définis avant de passer à une généralisation à l'ensemble des services de l'entreprise.
L'étude préalable se conclue par la rédaction d'un cahier des charges comprenant la solution envisagée, le bilan du retour sur investissement et la décision d'implantation.
Admin- Admin
- Messages : 132
Date d'inscription : 14/11/2008
Localisation : Alger -
Re: Découverte de connaissance a partir des données
Admin Lun 27 Juil - 15:18
1.2.2 Modèles de données
Niveau conceptuel
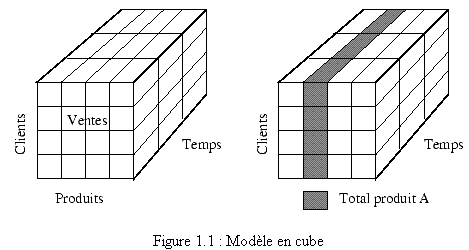
Le modèle conceptuel doit être simplifié au maximum pour permettre au plus grand nombre d'appréhender l'organisation des données, comprendre ce que l'entrepôt mémorise. On parle de modèle multidimensionnel, souvent représenté sous forme de cube, parce que les données seront toujours des faits à analyser suivant plusieurs dimensions. Par exemple, dans le cas de ventes de produits à des clients dans le temps (3 dimensions, un vrai cube), les faits sont les ventes, les dimensions sont les clients, les produits et le temps. Les interrogations s'interprètent souvent comme l'extraction d'un plan, d'une droite de ce cube (e.g. lister les ventes du produit A ou lister les ventes du produit A sur période de temps D), ou l'agrégation de données le long d'un plan ou d'une droite (e.g. Obtenir le total des ventes du produit A revient à sommer les éléments du plan indiqué en figure 1.1).
Un avantage évident de ce modèle est sa simplicité, dès que les mots ventes, clients, produits et temps sont précisés, désambiguisés. Il reprend les termes et la vision de l'entreprise de tout utilisateur final concerné par les processus de décision. Même si dans un entrepôt important il peut exister plusieurs cubes, parce qu'il est nécessaire de suivre plusieurs faits dans des directions parfois identiques, parfois différentes, l'utilisateur pourra accéder à des versions simplifiées, car plus ciblées, dans des datamarts.
Niveau logique
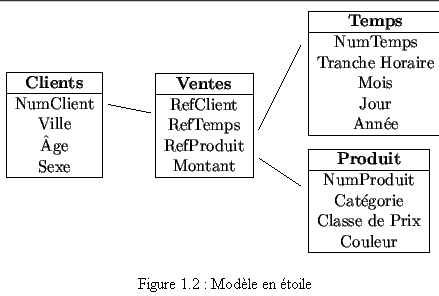
Au niveau logique, l'unité de base est la table comme dans le modèle relationnel. L'implantation classique consiste à considérer un modèle en étoile avec au centre la table des faits et les dimensions comme autant de branches à l'étoile. Les branches de l'étoile sont des relations de 1 à plusieurs, la table des faits est énorme contrairement aux tables des dimensions. Le modèle est en cela très dissymétrique en comparaison avec les modèles relationnels des bases de production. Encore une fois, la simplicité du modèle obtenu rend la construction en étoile très attrayante.
Les faits sont qualifiés par des champs qui sont le plus souvent numériques et cumulatifs comme des prix, des quantités et des clés évidemment pour relier les faits à chaque dimension. Les tables des dimensions sont caractérisées par des champs le plus souvent textuels. Dans l'exemple présenté en figure 1.2, nous nous limitons au suivi d'un seul fait : le montant des ventes. Un enregistrement dans la table des faits Ventes correspond à un total des ventes à un client dans une tranche horaire d'un jour précis, pour un produit choisi.
Il existe un modèle concurrent : le modèle en flocon. L'avantage mis en avant par les tenants de ce modèle est l'économie de place de stockage. Mais, le plus souvent, un examen approfondi montre que cette structure n'apporte rien, et complique même le modèle. Quand une hiérarchie apparaît dans une dimension, il est préférable de tout enregistrer dans une seule et même table formant une grande dimension. Par exemple, pour une dimension produit avec des catégories, puis des sous-catégories (et ainsi de suite), toutes les échelles sont conservées dans la même table de dimension. Il sera ensuite possible de naviguer (ou forer) par des opérations de zoom dans cette échelle (en anglais drill up et drill down).
Niveau conceptuel
Le modèle conceptuel doit être simplifié au maximum pour permettre au plus grand nombre d'appréhender l'organisation des données, comprendre ce que l'entrepôt mémorise. On parle de modèle multidimensionnel, souvent représenté sous forme de cube, parce que les données seront toujours des faits à analyser suivant plusieurs dimensions. Par exemple, dans le cas de ventes de produits à des clients dans le temps (3 dimensions, un vrai cube), les faits sont les ventes, les dimensions sont les clients, les produits et le temps. Les interrogations s'interprètent souvent comme l'extraction d'un plan, d'une droite de ce cube (e.g. lister les ventes du produit A ou lister les ventes du produit A sur période de temps D), ou l'agrégation de données le long d'un plan ou d'une droite (e.g. Obtenir le total des ventes du produit A revient à sommer les éléments du plan indiqué en figure 1.1).
Un avantage évident de ce modèle est sa simplicité, dès que les mots ventes, clients, produits et temps sont précisés, désambiguisés. Il reprend les termes et la vision de l'entreprise de tout utilisateur final concerné par les processus de décision. Même si dans un entrepôt important il peut exister plusieurs cubes, parce qu'il est nécessaire de suivre plusieurs faits dans des directions parfois identiques, parfois différentes, l'utilisateur pourra accéder à des versions simplifiées, car plus ciblées, dans des datamarts.
Niveau logique
Au niveau logique, l'unité de base est la table comme dans le modèle relationnel. L'implantation classique consiste à considérer un modèle en étoile avec au centre la table des faits et les dimensions comme autant de branches à l'étoile. Les branches de l'étoile sont des relations de 1 à plusieurs, la table des faits est énorme contrairement aux tables des dimensions. Le modèle est en cela très dissymétrique en comparaison avec les modèles relationnels des bases de production. Encore une fois, la simplicité du modèle obtenu rend la construction en étoile très attrayante.
Les faits sont qualifiés par des champs qui sont le plus souvent numériques et cumulatifs comme des prix, des quantités et des clés évidemment pour relier les faits à chaque dimension. Les tables des dimensions sont caractérisées par des champs le plus souvent textuels. Dans l'exemple présenté en figure 1.2, nous nous limitons au suivi d'un seul fait : le montant des ventes. Un enregistrement dans la table des faits Ventes correspond à un total des ventes à un client dans une tranche horaire d'un jour précis, pour un produit choisi.
Il existe un modèle concurrent : le modèle en flocon. L'avantage mis en avant par les tenants de ce modèle est l'économie de place de stockage. Mais, le plus souvent, un examen approfondi montre que cette structure n'apporte rien, et complique même le modèle. Quand une hiérarchie apparaît dans une dimension, il est préférable de tout enregistrer dans une seule et même table formant une grande dimension. Par exemple, pour une dimension produit avec des catégories, puis des sous-catégories (et ainsi de suite), toutes les échelles sont conservées dans la même table de dimension. Il sera ensuite possible de naviguer (ou forer) par des opérations de zoom dans cette échelle (en anglais drill up et drill down).
Admin- Admin
- Messages : 132
Date d'inscription : 14/11/2008
Localisation : Alger -
Re: Découverte de connaissance a partir des données
Admin Lun 27 Juil - 15:20
Avant de continuer reliez encore une autre fois, et essayer de bien comprendre touts les notions citées, et si vous n'arrivez pas a comprendre une chose faite le moi savoir.
Admin- Admin
- Messages : 132
Date d'inscription : 14/11/2008
Localisation : Alger -
Re: Découverte de connaissance a partir des données
Admin Lun 27 Juil - 17:06
1.2.3 Alimentation
L'alimentation est la procédure qui permet de transférer des données du système opérationnel vers l'entrepôt de données en les adaptant. La conception de cette opération est une tâche assez complexe. Elle doit être faite en collaboration avec les administrateurs des bases de production qui connaissent les données disponibles et vérifient la faisabilité des demandes. Il est nécessaire de déterminer quelles données seront chargées, quelles transformations et vérifications seront nécessaires, la périodicité et le moment auxquels les transferts auront lieu.
Traditionnellement, ce sont en grande partie des faits qui seront ajoutés. Les dimensions évoluent selon leur nature soit peu soit assez rapidement. Dans notre exemple, nous pouvons imaginer que la gamme des produits n'est pas très souvent modifiée. Par contre, de nouveaux clients seront certainement ajoutés mais bien moins que des dates. Le chargement implique aussi des problèmes physiques comme le recalcule des clés d'index. L'alimentation est ponctuée d'une procédure d'assurance qualité qui veillera à ce que tout se soit déroulé correctement avant la publication du nouveau jeu de données.
Transformations, vérifications
L'étude des besoins a déterminé le contenu de l'entrepôt en partant des desiderata des utilisateurs. Néanmoins, la forme, le contenu des données de production ne convient pas toujours immédiatement au format choisi pour les données de l'entrepôt. Par conséquent, des transformations sont souvent nécessaires.
Format
Le format physique des données provenant de la production peut ne pas être adéquat avec le système hôte de l'entrepôt. Des transformations de type sont parfois nécessaires (Système IBM vers système Unix...). Les données pouvant provenir de serveurs différents dans des services différents, il est nécessaire d'uniformiser les noms et les formats des données manipulées au niveau de l'entrepôt.
Consolidation
Selon les choix des unités pour les dimensions, des opérations de consolidation devront accompagner le chargement des données (par exemple sommer les ventes pour obtenir et enregistrer un total par jour et non pas toutes les transactions).
Uniformisation d'échelle
Pour éviter de trop grandes dispersions dans les valeurs numériques, une homogénéisation des échelles de valeurs est utile. Ne pas la réaliser peut pénaliser les outils d'analyse et de visualisation et peut-être simplement remplir inutilement les disques.
Autres
Des transformations qui permettent de mieux analyser les données sont aussi réalisées pendant la phase de chargement. Par exemple, la transformation de la date de naissance en âge, assure une plus grande lisibilité des données et permet de pallier les problèmes apparus avec l'introduction de la dimension temps.
Malgré les efforts réalisés pour assurer l'intégrité des données de production, des erreurs peuvent survenir, en particulier, lorsque les données proviennent de sources différentes (par exemple, il est fréquent qu'un même client soit mémorisé plusieurs fois sur différents serveurs). Parmi les points à vérifier, on peut citer:
Erreurs de saisie
Des doublons sont présents mais sont invisibles ; à cause des fautes de frappe: (Marcel dupont; 3,rue verte; Lille) et (Marcel dupond; 3,rue verte; Lille) sont certainement un seul et même client ; plusieurs membres d'un même foyer peuvent être présents ; ...
Intégrité de domaine
Un contrôle sur les domaines des valeurs permet de retrouver des valeurs aberrantes. De façon plus générale, des valeurs douteuses peuvent se rencontrer, comme par exemple des dates au 11 novembre 1911 (11/11/11) ou 1 janvier 1901 (01/01/01).
Informations manquantes
Des champs importants pour lesquels aucune valeur n'a été saisie peuvent pénaliser le processus de découverte d'information, ou bien encore avoir une signification particulière (ex: détection de fraudes). Il est parfois important d'insérer des valeurs par défaut significatives (comme NULL) plutôt que de laisser ces données vides.
Il convient de noter que les sources des données alimentant un entrepôt peuvent être hétérogènes. Les bases de production peuvent être nombreuses, différentes et délocalisées géographiquement. Des fichiers peuvent être achetées auprès d'entreprises qui se sont spécialisées dans la constitution et la revente de fichiers qui vont aussi entrer dans le processus d'alimentation de l'entrepôt. Les suites logicielles d'accompagnement d'entrepôts de données contiennent des outils susceptibles d'aider à développer des procédures d'alimentation qui prennent en compte ces problèmes de vérification et de normalisation.
Métadonnées
Des choix conceptuels, logiques et organisationnels ont été opérés tout au long de cette démarche d'informatisation du système d'information de décision. La perte de l'information sur ces choix peut induire de mauvaises interprétations. Donc, un annuaire spécialisé conserve toutes les informations (les métadonnées) au sujet du système d'information qui régit l'entrepôt. Cet annuaire contient entre autres choses :
* Les adresses et descriptions des objets de l'entrepôt : tables, champs, ... En particulier chaque donnée est définie par une description précise et claire, son origine, ... surtout lorsque les données proviennent de bases différentes et qu'elles peuvent avoir d'autres significations par ailleurs ;
* les utilisateurs, autorisations, ...;
* les règles de transformation, de vérification ;
* l'historique de l'entrepôt avec les dates de chargement, ...
Sans référentiel qui qualifie de façon précise ce que signifie chaque valeur dans la base, il n'est pas possible de conduire une analyse et interpréter les résultats. C'est ce rôle que joue l'annuaire des métadonnées.
Certification, publication
Comme nous l'avons montré précédemment, la cohérence de l'entrepôt est globale et ce n'est qu'à la fin de la procédure de chargement qu'il est possible de la vérifier. Une procédure de certification de la qualité des données chargées doit suivre le chargement. Cette procédure est particulière à l'entrepôt et ne peut être décrite précisément. Elle va par exemple vérifier la cohérence des données au niveau des activités. En cas de succès, la nouvelle version de l'entrepôt sera publiée. Dans le cas contraire, c'est souvent le chargement complet qui est annulé et repoussé à une date ultérieure. En fait, le chargement peut être vu comme une très grosse (et longue) transaction.
L'alimentation est la procédure qui permet de transférer des données du système opérationnel vers l'entrepôt de données en les adaptant. La conception de cette opération est une tâche assez complexe. Elle doit être faite en collaboration avec les administrateurs des bases de production qui connaissent les données disponibles et vérifient la faisabilité des demandes. Il est nécessaire de déterminer quelles données seront chargées, quelles transformations et vérifications seront nécessaires, la périodicité et le moment auxquels les transferts auront lieu.
Traditionnellement, ce sont en grande partie des faits qui seront ajoutés. Les dimensions évoluent selon leur nature soit peu soit assez rapidement. Dans notre exemple, nous pouvons imaginer que la gamme des produits n'est pas très souvent modifiée. Par contre, de nouveaux clients seront certainement ajoutés mais bien moins que des dates. Le chargement implique aussi des problèmes physiques comme le recalcule des clés d'index. L'alimentation est ponctuée d'une procédure d'assurance qualité qui veillera à ce que tout se soit déroulé correctement avant la publication du nouveau jeu de données.
Transformations, vérifications
L'étude des besoins a déterminé le contenu de l'entrepôt en partant des desiderata des utilisateurs. Néanmoins, la forme, le contenu des données de production ne convient pas toujours immédiatement au format choisi pour les données de l'entrepôt. Par conséquent, des transformations sont souvent nécessaires.
Format
Le format physique des données provenant de la production peut ne pas être adéquat avec le système hôte de l'entrepôt. Des transformations de type sont parfois nécessaires (Système IBM vers système Unix...). Les données pouvant provenir de serveurs différents dans des services différents, il est nécessaire d'uniformiser les noms et les formats des données manipulées au niveau de l'entrepôt.
Consolidation
Selon les choix des unités pour les dimensions, des opérations de consolidation devront accompagner le chargement des données (par exemple sommer les ventes pour obtenir et enregistrer un total par jour et non pas toutes les transactions).
Uniformisation d'échelle
Pour éviter de trop grandes dispersions dans les valeurs numériques, une homogénéisation des échelles de valeurs est utile. Ne pas la réaliser peut pénaliser les outils d'analyse et de visualisation et peut-être simplement remplir inutilement les disques.
Autres
Des transformations qui permettent de mieux analyser les données sont aussi réalisées pendant la phase de chargement. Par exemple, la transformation de la date de naissance en âge, assure une plus grande lisibilité des données et permet de pallier les problèmes apparus avec l'introduction de la dimension temps.
Malgré les efforts réalisés pour assurer l'intégrité des données de production, des erreurs peuvent survenir, en particulier, lorsque les données proviennent de sources différentes (par exemple, il est fréquent qu'un même client soit mémorisé plusieurs fois sur différents serveurs). Parmi les points à vérifier, on peut citer:
Erreurs de saisie
Des doublons sont présents mais sont invisibles ; à cause des fautes de frappe: (Marcel dupont; 3,rue verte; Lille) et (Marcel dupond; 3,rue verte; Lille) sont certainement un seul et même client ; plusieurs membres d'un même foyer peuvent être présents ; ...
Intégrité de domaine
Un contrôle sur les domaines des valeurs permet de retrouver des valeurs aberrantes. De façon plus générale, des valeurs douteuses peuvent se rencontrer, comme par exemple des dates au 11 novembre 1911 (11/11/11) ou 1 janvier 1901 (01/01/01).
Informations manquantes
Des champs importants pour lesquels aucune valeur n'a été saisie peuvent pénaliser le processus de découverte d'information, ou bien encore avoir une signification particulière (ex: détection de fraudes). Il est parfois important d'insérer des valeurs par défaut significatives (comme NULL) plutôt que de laisser ces données vides.
Il convient de noter que les sources des données alimentant un entrepôt peuvent être hétérogènes. Les bases de production peuvent être nombreuses, différentes et délocalisées géographiquement. Des fichiers peuvent être achetées auprès d'entreprises qui se sont spécialisées dans la constitution et la revente de fichiers qui vont aussi entrer dans le processus d'alimentation de l'entrepôt. Les suites logicielles d'accompagnement d'entrepôts de données contiennent des outils susceptibles d'aider à développer des procédures d'alimentation qui prennent en compte ces problèmes de vérification et de normalisation.
Métadonnées
Des choix conceptuels, logiques et organisationnels ont été opérés tout au long de cette démarche d'informatisation du système d'information de décision. La perte de l'information sur ces choix peut induire de mauvaises interprétations. Donc, un annuaire spécialisé conserve toutes les informations (les métadonnées) au sujet du système d'information qui régit l'entrepôt. Cet annuaire contient entre autres choses :
* Les adresses et descriptions des objets de l'entrepôt : tables, champs, ... En particulier chaque donnée est définie par une description précise et claire, son origine, ... surtout lorsque les données proviennent de bases différentes et qu'elles peuvent avoir d'autres significations par ailleurs ;
* les utilisateurs, autorisations, ...;
* les règles de transformation, de vérification ;
* l'historique de l'entrepôt avec les dates de chargement, ...
Sans référentiel qui qualifie de façon précise ce que signifie chaque valeur dans la base, il n'est pas possible de conduire une analyse et interpréter les résultats. C'est ce rôle que joue l'annuaire des métadonnées.
Certification, publication
Comme nous l'avons montré précédemment, la cohérence de l'entrepôt est globale et ce n'est qu'à la fin de la procédure de chargement qu'il est possible de la vérifier. Une procédure de certification de la qualité des données chargées doit suivre le chargement. Cette procédure est particulière à l'entrepôt et ne peut être décrite précisément. Elle va par exemple vérifier la cohérence des données au niveau des activités. En cas de succès, la nouvelle version de l'entrepôt sera publiée. Dans le cas contraire, c'est souvent le chargement complet qui est annulé et repoussé à une date ultérieure. En fait, le chargement peut être vu comme une très grosse (et longue) transaction.
Admin- Admin
- Messages : 132
Date d'inscription : 14/11/2008
Localisation : Alger -
Re: Découverte de connaissance a partir des données
Admin Lun 27 Juil - 17:07
1.3 Utilisation, exploitation
L'alimentation des entrepôts s'accompagne, après validation, de l'édition automatique des tableaux de bord les plus courants. Ils sont prédéfinis, réalisés par le service informatique, et sont le reflet d'un besoin explicitement demandé au moment de la conception. Souvent, ils sont insuffisants lorsqu'une anomalie est détectée ou lorsqu'un nouveau besoin s'exprime. L'utilisateur final doit alors pouvoir interroger les données en ligne à l'aide d'outils simples et conviviaux. Ces outils commencent à se généraliser. Les éditeurs les nomment (ou les classent) : reporting tools, managed queries, Executive Information Systems (EIS), OLAP tools (Online analytical Processing), ...bien que les différences entre tous ces systèmes ne soient pas toujours très nettes.
On suppose avoir défini un entrepôt de données pour lequel les données sont organisées selon un modèle en étoile. Nous allons préciser les outils attendus dans un tel environnement : outils de requête (SQL) et d'analyse multi-dimensionnelle ; les opérations possibles pour l'utilisateur en analyse multi-dimensionnelle ; les outils de visualisation.
1.3.1 Requêtes
Nous présentons ici les outils destinés à l'utilisateur final qui permettent d'extraire des données de l'entrepôt.
Les outils de création de rapport (reporting tools) extraient les données et proposent une mise en forme destinée à la diffusion : par impression ou par des services internet ou intranet. Ils sont très utilisés pour générer des tableaux de bord conventionnels, qui sont souvent composés et diffusés automatiquement et périodiquement sans demande spécifique des utilisateurs. Lorsque leur intégration dans le système d'information est réussie, ils mettent en évidence la structure multidimensionnelle et présentent les agrégats, supportent la navigation. Ils sont accessibles aux utilisateurs finals pour créer de nouveaux tableaux de bord. Certains (managed queries tools comme par exemple Business Object) ne sont pas spécialisés pour les entrepôts de données mais proposent une métacouche entre l'utilisateur final et le système d'information destinée à simplifier le vocabulaire, éviter le SQL.
Les progiciels (ex : SAS) dans ce domaine ont aussi réalisé une percée importante. Ils sont souvent qualifiés de EIS tools et ajoutent des analyses classiques et paramétrables pour les ventes, les achats ou la finance par exemple.
Les outils les plus adaptés sont certainement les outils OLAP, néanmoins, on pourra relever quelques défauts qui expliquent peut-être la difficulté qu'ils ont à s'imposer. À l'origine, E.F. Codd précurseur dans les bases de données relationnelles a aussi écrit 12 règles pour définir ce que signifie OLAP. Ces règles portent sur l'évidence de multiples dimensions, la transparence du système, l'accessibilité aux utilisateurs, la performance, l'intégration dans le client-server, l'extensibilité des dimensions, la navigation, la flexibilité,... Les éditeurs ont tenté de bâtir des outils se réclamant de ces règles. Malheureusement, il est difficile de vérifier les principes OLAP seulement avec le langage SQL. De ce fait, la plupart des outils sont maintenant des systèmes propriétaires non ouverts et non standardisés. De plus, ils ne peuvent pas à l'heure actuelle traiter des bases de données volumineuses.
1.3.2 Agrégats et navigation
L'opération de navigation (ou forage) permet d'obtenir des détails sur la signification d'un résultat en affinant une dimension ou en ajoutant une dimension. Elle apparaît dans de nombreux outils et doit (parce qu'elle est souvent coûteuse) être intégrée dans le système. Pour illustrer le forage, supposons qu'un utilisateur final demande les chiffres d'affaires par produit, et s'étonne d'un résultat pour un produit donné. Il aura sûrement l'envie d'en analyser les raisons. Une solution consisterait à ajouter la dimension temps, dans l'unité de temps trimestrielle pour trouver une variation saisonnière, dans l'unité hebdomadaire pour envisager l'effet week-end, ou encore la dimension magasin pour mettre en évidence un effet géographique.
Pour des raisons de performance, il est utile de précalculer et préenregistrer dans l'entrepôt des agrégations de données. Dans notre exemple, si des requêtes fréquemment formulées impliquent le calcul de la somme des ventes par produit et par trimestre, il est alors simple d'optimiser le temps de réponse du système en mémorisant ce calcul. On introduit une redondance dans l'entrepôt mais elle se justifie de deux façons : d'une part on privilégie le temps de réponse ; d'autre part, puisque par principe les données d'un entrepôt ne sont pas modifiées, il n'est pas possible de rendre la base incohérente.
C'est une fois de plus l'étude des besoins qui doit mettre en évidence la création des agrégats. Pour insister sur l'importance de mémoriser les résultats de calculs on peut noter que des machines sont parfois dédiées à leur exécution et leur diffusion : ce sont des serveurs d'agrégats.
La stratégie de mémorisation de ces agrégats peut prendre deux formes. La première solution consiste à créer de nouvelles tables de faits pour les agrégats. Toutes les dimensions inutiles ou incohérentes avec l'agrégat seront supprimées. La deuxième solution consiste à enrichir la table initiale des faits par les agrégats avec une information supplémentaire indiquant le niveau de regroupement. Ces deux solutions ont quasiment la même incidence sur les volumes.
Pour expliquer un résultat, il est parfois nécessaire de le comparer avec d'autres faits. Par exemple, la baisse des ventes pour le mois de janvier peut s'expliquer par une baisse des achats ou une rupture de stock. Si l'entrepôt est conçu pour suivre les ventes et les achats ou le stock, et si les dimensions selon lesquelles ces trois faits sont suivis sont identiques, on doit pouvoir réaliser un rapport unique. On parle alors de forage transversal ou drill across. C'est une opération qu'il faut réaliser avec beaucoup de soins car mettre en oeuvre une requête sur plusieurs tables de faits peut se révéler irréalisable. Engagée sans précautions, la requête va générer une table intermédiaire énorme qui sera le produit cartésien entre les deux tables de faits.
1.3.3 Visualisation
Les outils de visualisation sont très importants dans le processus de décision et peuvent intervenir à plusieurs niveaux. Ils sont utiles pour
1. découvrir de nouvelles informations, parce qu'une représentation permet de repérer plus simplement des singularités, des anomalies ;
2. présenter des résultats, dans l'optique d'une large diffusion, parce qu'un graphique est plus accessible qu'un tableau de chiffres ;
3. représenter un modèle issu d'une opération de fouille de données (représenter un arbre de décision, un ensemble des règles, un réseau de neurones...). Nous ne développons pas ce point.
Dans le premier cas, ils sont intégrés dans les outils d'analyse et doivent supporter des opérations comme comparer, modifier les échelles, retrouver les données correspondant à un point ou un objet tracé, zoomer sur des régions ou des sous-ensembles et enfin permettre la navigation (drill-up, drill down).
Lorsqu'il est nécessaire de présenter un objet reposant sur plusieurs dimensions sur un écran ou une feuille de papier, des problèmes bien connus apparaissent. Les représentations 3D ne sont pas toujours adaptées : les objets sont déformés, certains sont cachés... Des animations sont nécessaires pour faire pivoter la représentation. Les couleurs, utilisées en grand nombre, sont difficiles à choisir, facile à confondre. La visualisation scientifique reste un secteur de la recherche actif où vont se mêler des arguments informatiques, psychologiques, ...
Terminons en insistant sur l'importance du choix du type de graphique utilisé même en représentation 2D (surtout en situation de large diffusion). Un graphique en camembert représente une fonction de répartition (les parties en rapport avec le tout). Les courbes sont utiles lorsque les deux échelles sont numériques (et continues). Les histogrammes sont préférés quand une dimension est discrète (une liste de régions, une liste de produits). Souvent, l'axe des abscisses est réservé aux échelles respectant un ordre (des dates par exemple). Les superpositions de plusieurs séries sous forme d'aires ou de barres d'histogrammes sont réservées lorsque la somme des séries a un sens.
1.3.4 Supports physiques, optimisations
Nous terminons ce chapitre par quelques éléments à prendre en compte lors de l'implantation d'un entrepôt de données.
Calcul des volumes
C'est une évaluation nécessaire et d'ailleurs traditionnelle à réaliser au moment de la rédaction du cahier des charges lorsqu'on désire construire une base de données ou un entrepôt. Dès que les études logiques ont abouti, il est nécessaire d'estimer la place que les données occuperont sur disque.
Prenons par exemple le suivi des ventes d'une chaîne de 300 magasins suivant les dimensions temps, magasin, produit, promotion. Les faits suivis sont : le prix de vente, la quantité vendue, le prix d'achat, le nombre d'achats réalisé. Un enregistrement de la table des faits aura donc une structure logique de la forme :
Fait( RefTps,RefProduit,Refmagasin,Refpromo,
PrixVente,QtéVendue,PrixAchat,QtéAchat)
On estime conserver les enregistrements sur 2 ans jour par jour, soit 730 jours. Les 300 magasins vendent en moyenne 3000 produits par jour parmi 30000 possibles. Les produits ne bénéficient que d'une seule promotion dans un magasin à un jour donné. On aura donc 730× 300 × 3000 × 1 = 657 millions d'enregistrements dans la table des faits. Suivant le système choisi, et la représentation physique des clés (4 clés) et des entiers (4 champs numériques à suivre), on peut estimer la taille de la table des faits à environ 21 Go. Il reste à estimer la taille des index, la taille des tables de dimension etc ...
Matrices creuses
Avec l'exemple ci dessus, on s'aperçoit que la table des faits ne contient pas un enregistrement pour chaque élément dans chaque dimension. Par exemple, 300 des 3000 produits sont vendus chaque jour dans un magasin et chaque produit ne bénéficie pas d'une promotion. En revenant à la définition conceptuelle des données en cube, on interprète cette constatation en disant que beaucoup de cubes unitaires ne contiennent aucune donnée, formant ainsi comme une matrice creuse (i.e. comportant beaucoup de zéros). Cette propriété peut-être exploitée pour améliorer la performance des algorithmes et optimiser le stockage.
Le problème des clés et des index
La gestion des clefs et des index est un problème important dans ces grandes tables. Il faut envisager leur évolution, la possibilité de les étendre sans les régénérer. L'organisation physique sur disque est déterminante pour les questions d'efficacité. Toutes ces questions sont très spécifiques et dépendent des machines utilisées (machines parallèles) et du type d'accès aux données.
La table des faits aura des index pour chaque clé étrangère et bien sûr pour les regroupements les plus fréquents de clés étrangères. Dans notre exemple, l'index sur la clé étrangère RefProduit est utile pour retrouver rapidement les achats d'un produit donné. Un index sur RefProduit.RefTemps (les 2 champs à la fois) est utile pour retrouver les achats d'un produit donné dans un mois donné. Les tables de dimension sont souvent indexées suivant tous leurs champs.
Mais les gains les plus remarquables s'obtiennent par deux techniques : utiliser des machines parallèles et précalculer des agrégats.
Machines parallèles
L'utilisation de machines parallèles est très adéquat pour les entrepôts de données et peut-être plus simple à mettre en oeuvre que dans le cas du transactionnel. La caractéristique de n'accèder à l'entrepôt qu'en lecture permet de dupliquer des données, d'accepter plusieurs utilisateurs simultanés sans craindre des incohérences.
Les architectures parallèles considérées ici sont des machines à plusieurs processeurs qui partagent de la mémoire, du disque ou rien du tout. Un réseau de communication performant relie les processeurs. Ces machines améliorent les performances de plusieurs façons, suivant leur architecture, la répartition des données sur tous les disques et le grain de parallélisme envisagé. Le grain définit le niveau atomique ou indécomposable des tâches, soit encore le niveau auquel peut intervenir la mise en parallèle des tâches. On peut considérer que l'unité indécomposable est la requête, ou les opérations de base, comme la jointure, la sélection, le tri, le regroupement. Un pipe-line de tâches est aussi parfois possible. Par exemple, le résultat d'une sélection faite par un processeur est directement envoyé vers un second processeur qui effectue un tri et le tri peut commencer avant que la sélection soit terminée.
Si les données nécessaires à deux tâches exécutées en parallèle se trouvent sur la même unité de disque, l'exécution ne sera pas optimale, puisque les tâches devront partager une ressource, l'accès au disque. Inversement, un trop grand éclatement des données va pénaliser les tâches qui perdront du temps en communication. Dans cette approche, la répartition des données est donc très importante. Plusieurs solutions sont proposées mais aucune n'est universelle et c'est une étude au cas par cas qu'il convient de mener. Les répartitions usuelles tiennent compte d'une table de hachage, des clés, du schéma des données ou encore se réalisent à la demande.
Agrégats
Le précalcul de certains groupes les plus fréquemment demandés est l'optimisation la plus performante. Les gains vont d'un rapport de 10 à un rapport de 1000. Dans certains cas, des serveurs d'agrégats, des machines dédiées à distribuer des calculs intermédiaires sur les groupes, sont intégrées dans l'architecture de l'entrepôt.
L'alimentation des entrepôts s'accompagne, après validation, de l'édition automatique des tableaux de bord les plus courants. Ils sont prédéfinis, réalisés par le service informatique, et sont le reflet d'un besoin explicitement demandé au moment de la conception. Souvent, ils sont insuffisants lorsqu'une anomalie est détectée ou lorsqu'un nouveau besoin s'exprime. L'utilisateur final doit alors pouvoir interroger les données en ligne à l'aide d'outils simples et conviviaux. Ces outils commencent à se généraliser. Les éditeurs les nomment (ou les classent) : reporting tools, managed queries, Executive Information Systems (EIS), OLAP tools (Online analytical Processing), ...bien que les différences entre tous ces systèmes ne soient pas toujours très nettes.
On suppose avoir défini un entrepôt de données pour lequel les données sont organisées selon un modèle en étoile. Nous allons préciser les outils attendus dans un tel environnement : outils de requête (SQL) et d'analyse multi-dimensionnelle ; les opérations possibles pour l'utilisateur en analyse multi-dimensionnelle ; les outils de visualisation.
1.3.1 Requêtes
Nous présentons ici les outils destinés à l'utilisateur final qui permettent d'extraire des données de l'entrepôt.
Les outils de création de rapport (reporting tools) extraient les données et proposent une mise en forme destinée à la diffusion : par impression ou par des services internet ou intranet. Ils sont très utilisés pour générer des tableaux de bord conventionnels, qui sont souvent composés et diffusés automatiquement et périodiquement sans demande spécifique des utilisateurs. Lorsque leur intégration dans le système d'information est réussie, ils mettent en évidence la structure multidimensionnelle et présentent les agrégats, supportent la navigation. Ils sont accessibles aux utilisateurs finals pour créer de nouveaux tableaux de bord. Certains (managed queries tools comme par exemple Business Object) ne sont pas spécialisés pour les entrepôts de données mais proposent une métacouche entre l'utilisateur final et le système d'information destinée à simplifier le vocabulaire, éviter le SQL.
Les progiciels (ex : SAS) dans ce domaine ont aussi réalisé une percée importante. Ils sont souvent qualifiés de EIS tools et ajoutent des analyses classiques et paramétrables pour les ventes, les achats ou la finance par exemple.
Les outils les plus adaptés sont certainement les outils OLAP, néanmoins, on pourra relever quelques défauts qui expliquent peut-être la difficulté qu'ils ont à s'imposer. À l'origine, E.F. Codd précurseur dans les bases de données relationnelles a aussi écrit 12 règles pour définir ce que signifie OLAP. Ces règles portent sur l'évidence de multiples dimensions, la transparence du système, l'accessibilité aux utilisateurs, la performance, l'intégration dans le client-server, l'extensibilité des dimensions, la navigation, la flexibilité,... Les éditeurs ont tenté de bâtir des outils se réclamant de ces règles. Malheureusement, il est difficile de vérifier les principes OLAP seulement avec le langage SQL. De ce fait, la plupart des outils sont maintenant des systèmes propriétaires non ouverts et non standardisés. De plus, ils ne peuvent pas à l'heure actuelle traiter des bases de données volumineuses.
1.3.2 Agrégats et navigation
L'opération de navigation (ou forage) permet d'obtenir des détails sur la signification d'un résultat en affinant une dimension ou en ajoutant une dimension. Elle apparaît dans de nombreux outils et doit (parce qu'elle est souvent coûteuse) être intégrée dans le système. Pour illustrer le forage, supposons qu'un utilisateur final demande les chiffres d'affaires par produit, et s'étonne d'un résultat pour un produit donné. Il aura sûrement l'envie d'en analyser les raisons. Une solution consisterait à ajouter la dimension temps, dans l'unité de temps trimestrielle pour trouver une variation saisonnière, dans l'unité hebdomadaire pour envisager l'effet week-end, ou encore la dimension magasin pour mettre en évidence un effet géographique.
Pour des raisons de performance, il est utile de précalculer et préenregistrer dans l'entrepôt des agrégations de données. Dans notre exemple, si des requêtes fréquemment formulées impliquent le calcul de la somme des ventes par produit et par trimestre, il est alors simple d'optimiser le temps de réponse du système en mémorisant ce calcul. On introduit une redondance dans l'entrepôt mais elle se justifie de deux façons : d'une part on privilégie le temps de réponse ; d'autre part, puisque par principe les données d'un entrepôt ne sont pas modifiées, il n'est pas possible de rendre la base incohérente.
C'est une fois de plus l'étude des besoins qui doit mettre en évidence la création des agrégats. Pour insister sur l'importance de mémoriser les résultats de calculs on peut noter que des machines sont parfois dédiées à leur exécution et leur diffusion : ce sont des serveurs d'agrégats.
La stratégie de mémorisation de ces agrégats peut prendre deux formes. La première solution consiste à créer de nouvelles tables de faits pour les agrégats. Toutes les dimensions inutiles ou incohérentes avec l'agrégat seront supprimées. La deuxième solution consiste à enrichir la table initiale des faits par les agrégats avec une information supplémentaire indiquant le niveau de regroupement. Ces deux solutions ont quasiment la même incidence sur les volumes.
Pour expliquer un résultat, il est parfois nécessaire de le comparer avec d'autres faits. Par exemple, la baisse des ventes pour le mois de janvier peut s'expliquer par une baisse des achats ou une rupture de stock. Si l'entrepôt est conçu pour suivre les ventes et les achats ou le stock, et si les dimensions selon lesquelles ces trois faits sont suivis sont identiques, on doit pouvoir réaliser un rapport unique. On parle alors de forage transversal ou drill across. C'est une opération qu'il faut réaliser avec beaucoup de soins car mettre en oeuvre une requête sur plusieurs tables de faits peut se révéler irréalisable. Engagée sans précautions, la requête va générer une table intermédiaire énorme qui sera le produit cartésien entre les deux tables de faits.
1.3.3 Visualisation
Les outils de visualisation sont très importants dans le processus de décision et peuvent intervenir à plusieurs niveaux. Ils sont utiles pour
1. découvrir de nouvelles informations, parce qu'une représentation permet de repérer plus simplement des singularités, des anomalies ;
2. présenter des résultats, dans l'optique d'une large diffusion, parce qu'un graphique est plus accessible qu'un tableau de chiffres ;
3. représenter un modèle issu d'une opération de fouille de données (représenter un arbre de décision, un ensemble des règles, un réseau de neurones...). Nous ne développons pas ce point.
Dans le premier cas, ils sont intégrés dans les outils d'analyse et doivent supporter des opérations comme comparer, modifier les échelles, retrouver les données correspondant à un point ou un objet tracé, zoomer sur des régions ou des sous-ensembles et enfin permettre la navigation (drill-up, drill down).
Lorsqu'il est nécessaire de présenter un objet reposant sur plusieurs dimensions sur un écran ou une feuille de papier, des problèmes bien connus apparaissent. Les représentations 3D ne sont pas toujours adaptées : les objets sont déformés, certains sont cachés... Des animations sont nécessaires pour faire pivoter la représentation. Les couleurs, utilisées en grand nombre, sont difficiles à choisir, facile à confondre. La visualisation scientifique reste un secteur de la recherche actif où vont se mêler des arguments informatiques, psychologiques, ...
Terminons en insistant sur l'importance du choix du type de graphique utilisé même en représentation 2D (surtout en situation de large diffusion). Un graphique en camembert représente une fonction de répartition (les parties en rapport avec le tout). Les courbes sont utiles lorsque les deux échelles sont numériques (et continues). Les histogrammes sont préférés quand une dimension est discrète (une liste de régions, une liste de produits). Souvent, l'axe des abscisses est réservé aux échelles respectant un ordre (des dates par exemple). Les superpositions de plusieurs séries sous forme d'aires ou de barres d'histogrammes sont réservées lorsque la somme des séries a un sens.
1.3.4 Supports physiques, optimisations
Nous terminons ce chapitre par quelques éléments à prendre en compte lors de l'implantation d'un entrepôt de données.
Calcul des volumes
C'est une évaluation nécessaire et d'ailleurs traditionnelle à réaliser au moment de la rédaction du cahier des charges lorsqu'on désire construire une base de données ou un entrepôt. Dès que les études logiques ont abouti, il est nécessaire d'estimer la place que les données occuperont sur disque.
Prenons par exemple le suivi des ventes d'une chaîne de 300 magasins suivant les dimensions temps, magasin, produit, promotion. Les faits suivis sont : le prix de vente, la quantité vendue, le prix d'achat, le nombre d'achats réalisé. Un enregistrement de la table des faits aura donc une structure logique de la forme :
Fait( RefTps,RefProduit,Refmagasin,Refpromo,
PrixVente,QtéVendue,PrixAchat,QtéAchat)
On estime conserver les enregistrements sur 2 ans jour par jour, soit 730 jours. Les 300 magasins vendent en moyenne 3000 produits par jour parmi 30000 possibles. Les produits ne bénéficient que d'une seule promotion dans un magasin à un jour donné. On aura donc 730× 300 × 3000 × 1 = 657 millions d'enregistrements dans la table des faits. Suivant le système choisi, et la représentation physique des clés (4 clés) et des entiers (4 champs numériques à suivre), on peut estimer la taille de la table des faits à environ 21 Go. Il reste à estimer la taille des index, la taille des tables de dimension etc ...
Matrices creuses
Avec l'exemple ci dessus, on s'aperçoit que la table des faits ne contient pas un enregistrement pour chaque élément dans chaque dimension. Par exemple, 300 des 3000 produits sont vendus chaque jour dans un magasin et chaque produit ne bénéficie pas d'une promotion. En revenant à la définition conceptuelle des données en cube, on interprète cette constatation en disant que beaucoup de cubes unitaires ne contiennent aucune donnée, formant ainsi comme une matrice creuse (i.e. comportant beaucoup de zéros). Cette propriété peut-être exploitée pour améliorer la performance des algorithmes et optimiser le stockage.
Le problème des clés et des index
La gestion des clefs et des index est un problème important dans ces grandes tables. Il faut envisager leur évolution, la possibilité de les étendre sans les régénérer. L'organisation physique sur disque est déterminante pour les questions d'efficacité. Toutes ces questions sont très spécifiques et dépendent des machines utilisées (machines parallèles) et du type d'accès aux données.
La table des faits aura des index pour chaque clé étrangère et bien sûr pour les regroupements les plus fréquents de clés étrangères. Dans notre exemple, l'index sur la clé étrangère RefProduit est utile pour retrouver rapidement les achats d'un produit donné. Un index sur RefProduit.RefTemps (les 2 champs à la fois) est utile pour retrouver les achats d'un produit donné dans un mois donné. Les tables de dimension sont souvent indexées suivant tous leurs champs.
Mais les gains les plus remarquables s'obtiennent par deux techniques : utiliser des machines parallèles et précalculer des agrégats.
Machines parallèles
L'utilisation de machines parallèles est très adéquat pour les entrepôts de données et peut-être plus simple à mettre en oeuvre que dans le cas du transactionnel. La caractéristique de n'accèder à l'entrepôt qu'en lecture permet de dupliquer des données, d'accepter plusieurs utilisateurs simultanés sans craindre des incohérences.
Les architectures parallèles considérées ici sont des machines à plusieurs processeurs qui partagent de la mémoire, du disque ou rien du tout. Un réseau de communication performant relie les processeurs. Ces machines améliorent les performances de plusieurs façons, suivant leur architecture, la répartition des données sur tous les disques et le grain de parallélisme envisagé. Le grain définit le niveau atomique ou indécomposable des tâches, soit encore le niveau auquel peut intervenir la mise en parallèle des tâches. On peut considérer que l'unité indécomposable est la requête, ou les opérations de base, comme la jointure, la sélection, le tri, le regroupement. Un pipe-line de tâches est aussi parfois possible. Par exemple, le résultat d'une sélection faite par un processeur est directement envoyé vers un second processeur qui effectue un tri et le tri peut commencer avant que la sélection soit terminée.
Si les données nécessaires à deux tâches exécutées en parallèle se trouvent sur la même unité de disque, l'exécution ne sera pas optimale, puisque les tâches devront partager une ressource, l'accès au disque. Inversement, un trop grand éclatement des données va pénaliser les tâches qui perdront du temps en communication. Dans cette approche, la répartition des données est donc très importante. Plusieurs solutions sont proposées mais aucune n'est universelle et c'est une étude au cas par cas qu'il convient de mener. Les répartitions usuelles tiennent compte d'une table de hachage, des clés, du schéma des données ou encore se réalisent à la demande.
Agrégats
Le précalcul de certains groupes les plus fréquemment demandés est l'optimisation la plus performante. Les gains vont d'un rapport de 10 à un rapport de 1000. Dans certains cas, des serveurs d'agrégats, des machines dédiées à distribuer des calculs intermédiaires sur les groupes, sont intégrées dans l'architecture de l'entrepôt.
Admin- Admin
- Messages : 132
Date d'inscription : 14/11/2008
Localisation : Alger -
Re: Découverte de connaissance a partir des données
Admin Lun 27 Juil - 17:43
Pour voir comment on construit un entrepôt de données en pratique, je vous suggère de visualiser ces videos
http://www.jumpstarttv.com/channel.aspx?cat=9f88717f-8537-4f44-bdd1-f228abf9e399
une confèrence entière de 1h53 mn en streaming sur les entropots de données
rtsp://streamer.utsa.edu/Static/OIT/Data_Warehousing_Presentation.rm
http://www.jumpstarttv.com/channel.aspx?cat=9f88717f-8537-4f44-bdd1-f228abf9e399
une confèrence entière de 1h53 mn en streaming sur les entropots de données
rtsp://streamer.utsa.edu/Static/OIT/Data_Warehousing_Presentation.rm
Admin- Admin
- Messages : 132
Date d'inscription : 14/11/2008
Localisation : Alger -
Re: Découverte de connaissance a partir des données
Admin Sam 8 Aoû - 17:13
Chapitre 2 Processus de découverte d'information
* Préparation des données
* Nettoyage
* Enrichissement
* Codage, normalisation
* Fouille
* Validation
Nous présentons dans ce chapitre le processus complet d'extraction de connaissances. Nous nous limitons au traitement de données structurées. Il n'est pas question ici de recherche dans des textes ou des images, mais uniquement à partir de données. S'il est possible d'extraire de l'information à partir de toute source de données, l'existence d'un entrepôt diminue le temps de réalisation d'un projet.
Le processus que nous présentons maintenant est découpé en six parties : préparation, nettoyage, enrichissement, codage, fouille et validation. L'enchaînement des différentes étapes est présenté dans la figure 2.1.
Le déroulement d'un projet n'est pas linéaire. On peut constater dans l'étape de validation que les performances obtenues ne sont pas suffisantes ou que les utilisateurs du domaine jugent l'information inexploitable, il s'agira alors de choisir une autre méthode de fouille, ou de remettre en cause les codages, ou de chercher à enrichir les données. On évalue dans un projet le temps passé à l'étape de fouille de données (qui est l'étape de découverte d'informations proprement dite) à moins de 20% du temps. Par conséquent, plus de 80% du temps est dédié aux opérations de sélection, nettoyage, enrichissement et codage.
Nous présentons maintenant l'exemple qui nous servira pour illustrer chaque étape du processus. Cet exemple est issu du livre de P. Adriaans et D. Zantige [AZ96].
Un éditeur vend 5 sortes de magazines : sport, voiture, maison, musique et BD. Il souhaite mieux étudier ses clients pour découvrir de nouveaux marchés ou vendre plus de magazines à ses clients habituels. Les questions qu'il se pose sont :
1. << Combien de personnes ont pris un abonnement à un magazine de sport cette année ? >>
2. << A-t-on vendu plus d'abonnements de magazines de sport cette année que l'année dernière ? >>
3. << Est-ce que les acheteurs de magazines de BD sont aussi amateurs de sport ? >>
4. << Quelles sont les caractéristiques principales de mes lecteurs de magazines de voiture ? >>
5. << Peut-on prévoir les pertes de clients et prévoir des mesures pour les diminuer ? >>
Les questions qui sont proposées ici sont de natures différentes et mettent en jeu des processus différents.
De simples requêtes SQL sont suffisantes pour répondre aux deux premières questions. Les données recherchées dans ce cas ne sont que le résultat d'un calcul simple sur un ou des groupes d'enregistrements. Ce qui distingue ces deux premières questions, c'est la notion de temps et la comparaison. Pour établir cette comparaison, les données doivent être présentes dans la base, ce qui n'est pas toujours le cas pour les bases opérationnelles. Nous pouvons donc supposer que la requête 1 est réalisable sans technique particulière à partir des données opérationnelles sous réserve d'indexations suffisantes des tables concernées. La seule difficulté est de ne pas pénaliser le serveur transactionnel par des requêtes trop longues.
La requête 2 nécessite de conserver toutes les dates de souscription même pour les abonnements résiliés. Nous pouvons imaginer aussi que l'utilisateur émettra une grande variété de requêtes de ce type. Nous supposons alors que ces questions seront résolues à l'aide d'outils de création de requêtes multidimensionnelles de type OLAP.
La question 3 est un exemple simplifié de problème où l'on demande si les données vérifient une règle. La réponse pourrait se formuler par une valeur estimant la probabilité que la règle soit vraie. Souvent, des outils statistiques sont utilisés. Cette question peut être généralisée. On pourrait chercher des associations fréquentes entre acheteurs de magazine pour effectuer des actions promotionnelles. On pourrait également introduire une composante temporelle pour chercher si le fait d'être lecteur d'un magazine implique d'être, plus tard, lecteur d'un autre magazine.
La question 4 est beaucoup plus ouverte. La problématique ici est de trouver une règle et non plus de la vérifier ou de l'utiliser. C'est pour ce type de question que l'on met en oeuvre des outils de fouille de données et donc le processus décrit ci-dessous.
La question 5 est également une question ouverte. Il faut pour la résoudre disposer d'indicateurs qui pourraient sur notre exemple être : les durées d'abonnement, les délais de paiement, ... Ce type de question a une forte composante temporelle. Elle nécessite des données historiques. Elle a de nombreuses applications dans le domaine bancaire, par exemple.
Le processus de KDD utilise des outils de création de requêtes, des outils statistiques et des outils de fouille de données. Là encore, nous nous apercevons qu'une très grande partie des problèmes de décision se traite avec des outils simples. La fouille de données quand elle est nécessaire, suit souvent une analyse des données simple (OLAP) ou statistique.
2.1 Préparation des données
Dans notre exemple, nous avons identifié quelques objectifs précis, exprimés sous forme de questions.
La préparation des données consiste dans un premier temps à obtenir des données en accord avec les objectifs que l'on s'impose. Ces données proviennent le plus souvent de bases de production ou d'entrepôts. Les données sont structurées en champs typés (dans un domaine de définition).
Dans l'exemple, nous partons d'une liste des souscriptions d'abonnements avec cinq champs (voir figure 2.2).

Ces données sont tout d'abord copiées sur une machine adéquate, pour des questions de performance, mais surtout parce qu'elles seront modifiées.
L'obtention des données est souvent réalisée à l'aide d'outils de requêtage (OLAP, SQL,...).
Il faut, dès a présent, noter que l'on ne peut résoudre des problèmes que si l'on dispose des données nécessaires. Il semble, par exemple, impossible de s'attaquer à la question 5 de notre exemple avec les données dont nous disposons.
2.2 Nettoyage
Il y a évidemment de nombreux points communs entre nettoyage avant l'alimentation des entrepôts (1.2.3) et avant la fouille. Bien sûr, lorsque les données proviennent d'un entrepôt, le travail est simplifié mais reste néanmoins nécessaire : nous avons maintenant un projet bien défini, précis et les données doivent être les plus adaptées possibles.
Reprenons quelques remarques citées dans le chapitre précédent.
Doublons, erreurs de saisie
Les doublons peuvent se révéler gênants parce qu'ils vont donner plus d'importance aux valeur répétées. Une erreur de saisie pourra à l'inverse occulter une répétition.
Dans notre exemple, les clients numéro 23134 et 23130 sont certainement un seul et même client, malgré la légère différence d'orthographe.
Intégrité de domaine
Un contrôle sur les domaines des valeurs permet de retrouver des valeurs aberrantes.
Dans notre exemple, la date de naissance du client 23130 (11/11/11) semble plutôt correspondre à une erreur de saisie ou encore à une valeur par défaut en remplacement d'une valeur manquante.
Informations manquantes
C'est le terme utilisé pour désigner le cas où des champs ne contiennent aucune donnée. Parfois, il est intéressant de conserver ces enregistrements car l'absence d'information peut être une information (ex: détection de fraudes). D'autre part, les valeurs contenues dans les autres champs risquent aussi d'être utiles.
Dans notre exemple, nous n'avons pas le type de magazine pour le client 25312. Il sera écarté de notre ensemble. L'enregistrement du client 43241 sera conservé bien que l'adresse ne soit pas connue.
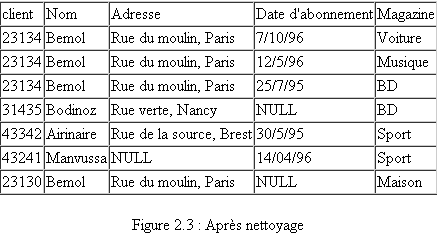
Là encore, le langage SQL est utilisé pour la recherche de doublons et des informations manquantes.
* Préparation des données
* Nettoyage
* Enrichissement
* Codage, normalisation
* Fouille
* Validation
Nous présentons dans ce chapitre le processus complet d'extraction de connaissances. Nous nous limitons au traitement de données structurées. Il n'est pas question ici de recherche dans des textes ou des images, mais uniquement à partir de données. S'il est possible d'extraire de l'information à partir de toute source de données, l'existence d'un entrepôt diminue le temps de réalisation d'un projet.
Le processus que nous présentons maintenant est découpé en six parties : préparation, nettoyage, enrichissement, codage, fouille et validation. L'enchaînement des différentes étapes est présenté dans la figure 2.1.
Le déroulement d'un projet n'est pas linéaire. On peut constater dans l'étape de validation que les performances obtenues ne sont pas suffisantes ou que les utilisateurs du domaine jugent l'information inexploitable, il s'agira alors de choisir une autre méthode de fouille, ou de remettre en cause les codages, ou de chercher à enrichir les données. On évalue dans un projet le temps passé à l'étape de fouille de données (qui est l'étape de découverte d'informations proprement dite) à moins de 20% du temps. Par conséquent, plus de 80% du temps est dédié aux opérations de sélection, nettoyage, enrichissement et codage.
Nous présentons maintenant l'exemple qui nous servira pour illustrer chaque étape du processus. Cet exemple est issu du livre de P. Adriaans et D. Zantige [AZ96].
Un éditeur vend 5 sortes de magazines : sport, voiture, maison, musique et BD. Il souhaite mieux étudier ses clients pour découvrir de nouveaux marchés ou vendre plus de magazines à ses clients habituels. Les questions qu'il se pose sont :
1. << Combien de personnes ont pris un abonnement à un magazine de sport cette année ? >>
2. << A-t-on vendu plus d'abonnements de magazines de sport cette année que l'année dernière ? >>
3. << Est-ce que les acheteurs de magazines de BD sont aussi amateurs de sport ? >>
4. << Quelles sont les caractéristiques principales de mes lecteurs de magazines de voiture ? >>
5. << Peut-on prévoir les pertes de clients et prévoir des mesures pour les diminuer ? >>
Les questions qui sont proposées ici sont de natures différentes et mettent en jeu des processus différents.
De simples requêtes SQL sont suffisantes pour répondre aux deux premières questions. Les données recherchées dans ce cas ne sont que le résultat d'un calcul simple sur un ou des groupes d'enregistrements. Ce qui distingue ces deux premières questions, c'est la notion de temps et la comparaison. Pour établir cette comparaison, les données doivent être présentes dans la base, ce qui n'est pas toujours le cas pour les bases opérationnelles. Nous pouvons donc supposer que la requête 1 est réalisable sans technique particulière à partir des données opérationnelles sous réserve d'indexations suffisantes des tables concernées. La seule difficulté est de ne pas pénaliser le serveur transactionnel par des requêtes trop longues.
La requête 2 nécessite de conserver toutes les dates de souscription même pour les abonnements résiliés. Nous pouvons imaginer aussi que l'utilisateur émettra une grande variété de requêtes de ce type. Nous supposons alors que ces questions seront résolues à l'aide d'outils de création de requêtes multidimensionnelles de type OLAP.
La question 3 est un exemple simplifié de problème où l'on demande si les données vérifient une règle. La réponse pourrait se formuler par une valeur estimant la probabilité que la règle soit vraie. Souvent, des outils statistiques sont utilisés. Cette question peut être généralisée. On pourrait chercher des associations fréquentes entre acheteurs de magazine pour effectuer des actions promotionnelles. On pourrait également introduire une composante temporelle pour chercher si le fait d'être lecteur d'un magazine implique d'être, plus tard, lecteur d'un autre magazine.
La question 4 est beaucoup plus ouverte. La problématique ici est de trouver une règle et non plus de la vérifier ou de l'utiliser. C'est pour ce type de question que l'on met en oeuvre des outils de fouille de données et donc le processus décrit ci-dessous.
La question 5 est également une question ouverte. Il faut pour la résoudre disposer d'indicateurs qui pourraient sur notre exemple être : les durées d'abonnement, les délais de paiement, ... Ce type de question a une forte composante temporelle. Elle nécessite des données historiques. Elle a de nombreuses applications dans le domaine bancaire, par exemple.
Le processus de KDD utilise des outils de création de requêtes, des outils statistiques et des outils de fouille de données. Là encore, nous nous apercevons qu'une très grande partie des problèmes de décision se traite avec des outils simples. La fouille de données quand elle est nécessaire, suit souvent une analyse des données simple (OLAP) ou statistique.
2.1 Préparation des données
Dans notre exemple, nous avons identifié quelques objectifs précis, exprimés sous forme de questions.
La préparation des données consiste dans un premier temps à obtenir des données en accord avec les objectifs que l'on s'impose. Ces données proviennent le plus souvent de bases de production ou d'entrepôts. Les données sont structurées en champs typés (dans un domaine de définition).
Dans l'exemple, nous partons d'une liste des souscriptions d'abonnements avec cinq champs (voir figure 2.2).
Ces données sont tout d'abord copiées sur une machine adéquate, pour des questions de performance, mais surtout parce qu'elles seront modifiées.
L'obtention des données est souvent réalisée à l'aide d'outils de requêtage (OLAP, SQL,...).
Il faut, dès a présent, noter que l'on ne peut résoudre des problèmes que si l'on dispose des données nécessaires. Il semble, par exemple, impossible de s'attaquer à la question 5 de notre exemple avec les données dont nous disposons.
2.2 Nettoyage
Il y a évidemment de nombreux points communs entre nettoyage avant l'alimentation des entrepôts (1.2.3) et avant la fouille. Bien sûr, lorsque les données proviennent d'un entrepôt, le travail est simplifié mais reste néanmoins nécessaire : nous avons maintenant un projet bien défini, précis et les données doivent être les plus adaptées possibles.
Reprenons quelques remarques citées dans le chapitre précédent.
Doublons, erreurs de saisie
Les doublons peuvent se révéler gênants parce qu'ils vont donner plus d'importance aux valeur répétées. Une erreur de saisie pourra à l'inverse occulter une répétition.
Dans notre exemple, les clients numéro 23134 et 23130 sont certainement un seul et même client, malgré la légère différence d'orthographe.
Intégrité de domaine
Un contrôle sur les domaines des valeurs permet de retrouver des valeurs aberrantes.
Dans notre exemple, la date de naissance du client 23130 (11/11/11) semble plutôt correspondre à une erreur de saisie ou encore à une valeur par défaut en remplacement d'une valeur manquante.
Informations manquantes
C'est le terme utilisé pour désigner le cas où des champs ne contiennent aucune donnée. Parfois, il est intéressant de conserver ces enregistrements car l'absence d'information peut être une information (ex: détection de fraudes). D'autre part, les valeurs contenues dans les autres champs risquent aussi d'être utiles.
Dans notre exemple, nous n'avons pas le type de magazine pour le client 25312. Il sera écarté de notre ensemble. L'enregistrement du client 43241 sera conservé bien que l'adresse ne soit pas connue.
Là encore, le langage SQL est utilisé pour la recherche de doublons et des informations manquantes.
Admin- Admin
- Messages : 132
Date d'inscription : 14/11/2008
Localisation : Alger -
Re: Découverte de connaissance a partir des données
Admin Sam 8 Aoû - 17:13
2.3 Enrichissement
On peut avoir recours à d'autres bases, achetées ou produites en un autre lieu, pour enrichir nos données. L'opération va se traduire par l'ajout de nouveaux champs en conservant souvent le même nombre d'enregistrements.
Une première difficulté ici est de pouvoir relier des données qui parfois sont hétérogènes. Des problèmes de format de données apparaissent et des conversions sont souvent nécessaires. Une deuxième difficulté est l'introduction de nouvelles valeurs manquantes ou aberrantes et la phase de nettoyage sera certainement de nouveau utile.
Dans l'exemple, supposons que nous ayons accès à des informations sur les clients (voir figure 2.4).

2.4 Codage, normalisation
À ce stade du processus, les choix sont particulièrement guidés par l'algorithme de fouille utilisé et des ajustements des choix de codage sont souvent nécessaires.
Regroupements
Certains attributs prennent un très grand nombre de valeurs discrètes. C'est typiquement le cas des adresses. Lorsqu'il est important de considérer ces attributs pour la fouille de données il est obligatoire d'opérer des regroupements et ainsi obtenir un nombre de valeurs raisonnable.
Dans l'exemple, nous regroupons les adresses en 2 régions : Paris, province.
Attributs discrets
Les attributs discrets prennent leurs valeurs (souvent textuelles) dans un ensemble fini donné. C'est le cas de la colonne magazine dans notre exemple qui peut prendre les valeurs Sport, BD, Voiture, Maison, Musique.
Deux représentations sont possibles pour ces données : une représentation verticale telle qu'elle est présentée en figure 2.3 ou une représentation horizontale ou éclatée (figure 2.5).

La représentation horizontale est plus adaptée à la fouille de données et certains calculs sont simplifiés. Par exemple, la somme de la colonne sport que divise le nombre d'enregistrements calcule le pourcentage de clients ayant souscrit un abonnement à un magazine de sport. Notons que la date d'abonnement dépend du type de magazine. De façon générale, la modification présentée en figure 2.5 peut induire une perte d'information pour tous les champs en dépendance fonctionnelle avec le champ transformé. Nous choisissons de transformer le champ date d'abonnement en date du plus vieil abonnement. Il est à noter que cette transformation ne nous permet plus espérer générer des règles de la forme : un acheteur de BD s'abonne à un magazine de musique dans les deux ans qui suivent.
Dans notre exemple, le même codage en deux valeurs 0 et 1 sera réalisé avec les champs Oui/Non issus de l'enrichissement.
Changements de type
Pour certaines manipulations, comme des calculs de distance, des calculs de moyenne, il est préférable de modifier les types de certains attributs. Dans notre exemple, la date de naissance et la date d'abonnement ne permettent pas d'effectuer simplement des comparaisons, des différences. Nous pouvons les convertir en âge ou en durée.
Uniformisation d'échelle
Certains algorithmes, comme la méthode des plus proches voisins, sont basés sur des calculs de distance entre enregistrements. Des variations d'échelle selon les attributs sont autant de perturbations possibles pour ces algorithmes. Des échelles très << étirées >> vont artificiellement rendre des dimensions trop << vides >>.
C'est typiquement le cas pour le champ Revenus dans notre exemple. Les centaines de francs ne sont pas significatives ici. Nous convertissons donc les revenus en les divisant par mille. L'intervalle de valeurs est alors dans la même échelle que les dates de naissance et les durées d'abonnement.

2.5 Fouille
La fouille de données est le coeur du processus car elle permet d'extraire de l'information des données. Néanmoins, c'est souvent une étape difficile à mettre en oeuvre, coûteuse et dont les résultats doivent être interprétés et relativisés. Il faut aussi noter qu'en situation réelle, pour l'aide à la décision, une très grande majorité des résultats recherchés s'obtient uniquement par requêtes, par analyse multi-dimensionnelle ou grâce aux outils de visualisation.
Une approche traditionnelle pour découvrir ou expliquer un phénomène est de
1. regarder, explorer,
2. établir un modèle ou une hypothèse,
3. essayer de le contredire ou le vérifier comme en 1 ; recommencer le point 2 jusqu'à obtenir une réponse de qualité satisfaisante.
La partie 1 est traditionnellement réalisée avec des outils de reporting ou d'analyse multidimensionnelle. La partie 2 est une hypothèse émise par l'uilisateur. On peut voir les outils de fouille de données comme des procédures qui permettent de faciliter ou encore d'automatiser ce processus.
La qualité du modèle obtenu se mesure selon les critères suivants :
* Rapide à créer ;
* rapide à utiliser ;
* compréhensible pour l'utilisateur ;
* les performances sont bonnes ; Le modèle est fiable ;
* les performances ne se dégradent pas dans le temps ;
* Il évolue facilement.
Il va de soit qu'aucun modèle n'aura toutes ces qualités. Il n'existe pas de meilleure méthode de fouille. Il faudra faire des compromis selon les besoins dégagés et les caractéristiques connues des outils. Dans le chapitre 2.5 nous en présentons quelques unes avec leurs avantages et inconvénients, des indications pour mieux les choisir. Pour une utilisation optimale, une combinaison de méthodes est recommandée. On peut rapidement donner 3 catégories :
Classification, régression, prédiction
Il s'agit de trouver une classe ou une valeur selon un ensemble de descriptions. Ce sont des outils très utilisés. Les algorithmes reposent sur des arbres de décision, des réseaux de neurones, la règle de Bayes, les k plus proches voisins.
Association, sequencing
Il s'agit de trouver des similarités ou des associations. Le sequencing est le terme anglais utilisé pour préciser que l'association se fera dans le temps. Par exemple, si j'achète un couffin aujourd'hui, j'ai trois fois plus de chance dans 3 mois d'acheter un lit bébé (sequencing) ou encore Si j'achète des pâtes et de la purée de tomates, j'ai deux fois plus de chance d'acheter aussi du parmesan (association).
Segmentation
La problématique est de trouver des groupes homogènes dans une population. On utilise souvent les algorithmes des k-moyennes ou de Kohonen. La difficulté essentielle dans ce type de construction est la validation qui nécessite l'intervention d'experts humains.
2.6 Validation
Les méthodes de validation vont déprendre de la nature de la tâche et du problème considéré. Nous distinguerons deux modes de validation : statistique et par expertise.
Pour certains domaines d'application (le diagnostic médical, par exemple), il est essentiel que le modèle produit soit compréhensible. Il y a donc une première validation du modèle produit par l'expert, celle-ci peut être complétée par une validation statistique sur des bases de cas existantes.
Pour les problèmes d'apprentissage non supervisé (segmentation, association), la validation est essentiellement du ressort de l'expert. Pour la segmentation, le programme construit des groupes homogènes, un expert peut juger de la pertinence des groupes constitués. La encore, on peut combiner avec une validation statistique sur un problème précis utilisant cette segmentation. Pour la recherche des règles d'association, c'est l'expert du domaine qui jugera de la pertinence des règles, en effet, l'algorithme, s'il fournit des règles porteuses d'information, produit également des règles triviales et sans intérêt.
Pour la validation statistique, la première tâche à réaliser consiste à utiliser les méthodes de base de statistique descriptive. L'objectif est d'obtenir des informations qui permettront de juger le résultat obtenu, ou d'estimer la qualité ou les biais des données d'apprentissage.
1. Calculer les moyennes et variances des attributs.
2. Si possible, calculer la corrélation entre certains champs.
3. Déterminer la classe majoritaire dans le cas de la classification.
Pour la classification supervisée, la deuxième tâche consiste à décomposer les données en plusieurs ensembles disjoints. L'objectif est de garder des données pour estimer les erreurs des modèles ou de les comparer. Il est souvent recommandé de constituer:
* Un ensemble d'apprentissage.
* Un ensemble de test.
* Un ensemble de validation.
Au moins deux ensembles sont nécessaires : l'ensemble d'apprentissage permet de générer le modèle, l'ensemble test permet d'évaluer l'erreur réelle du modèle sur un ensemble indépendant évitant ainsi un biais d'apprentissage. Lorsqu'il s'agit de tester plusieurs modèles et de les comparer, on peut sélectionner le meilleur modèle selon ses performances sur l'ensemble test et ensuite évaluer son erreur réelle sur l'ensemble de validation.
Lorsqu'on ne dispose pas de suffisamment d'exemples on peut se permettre d'apprendre et d'estimer les erreurs avec un même ensemble par la technique de validation croisée. . La validation croisée ne construit pas de modèle utilisable mais ne sert qu'à estimer l'erreur réelle d'un modèle selon l'algorithme suivant :

On peut avoir recours à d'autres bases, achetées ou produites en un autre lieu, pour enrichir nos données. L'opération va se traduire par l'ajout de nouveaux champs en conservant souvent le même nombre d'enregistrements.
Une première difficulté ici est de pouvoir relier des données qui parfois sont hétérogènes. Des problèmes de format de données apparaissent et des conversions sont souvent nécessaires. Une deuxième difficulté est l'introduction de nouvelles valeurs manquantes ou aberrantes et la phase de nettoyage sera certainement de nouveau utile.
Dans l'exemple, supposons que nous ayons accès à des informations sur les clients (voir figure 2.4).
2.4 Codage, normalisation
À ce stade du processus, les choix sont particulièrement guidés par l'algorithme de fouille utilisé et des ajustements des choix de codage sont souvent nécessaires.
Regroupements
Certains attributs prennent un très grand nombre de valeurs discrètes. C'est typiquement le cas des adresses. Lorsqu'il est important de considérer ces attributs pour la fouille de données il est obligatoire d'opérer des regroupements et ainsi obtenir un nombre de valeurs raisonnable.
Dans l'exemple, nous regroupons les adresses en 2 régions : Paris, province.
Attributs discrets
Les attributs discrets prennent leurs valeurs (souvent textuelles) dans un ensemble fini donné. C'est le cas de la colonne magazine dans notre exemple qui peut prendre les valeurs Sport, BD, Voiture, Maison, Musique.
Deux représentations sont possibles pour ces données : une représentation verticale telle qu'elle est présentée en figure 2.3 ou une représentation horizontale ou éclatée (figure 2.5).
La représentation horizontale est plus adaptée à la fouille de données et certains calculs sont simplifiés. Par exemple, la somme de la colonne sport que divise le nombre d'enregistrements calcule le pourcentage de clients ayant souscrit un abonnement à un magazine de sport. Notons que la date d'abonnement dépend du type de magazine. De façon générale, la modification présentée en figure 2.5 peut induire une perte d'information pour tous les champs en dépendance fonctionnelle avec le champ transformé. Nous choisissons de transformer le champ date d'abonnement en date du plus vieil abonnement. Il est à noter que cette transformation ne nous permet plus espérer générer des règles de la forme : un acheteur de BD s'abonne à un magazine de musique dans les deux ans qui suivent.
Dans notre exemple, le même codage en deux valeurs 0 et 1 sera réalisé avec les champs Oui/Non issus de l'enrichissement.
Changements de type
Pour certaines manipulations, comme des calculs de distance, des calculs de moyenne, il est préférable de modifier les types de certains attributs. Dans notre exemple, la date de naissance et la date d'abonnement ne permettent pas d'effectuer simplement des comparaisons, des différences. Nous pouvons les convertir en âge ou en durée.
Uniformisation d'échelle
Certains algorithmes, comme la méthode des plus proches voisins, sont basés sur des calculs de distance entre enregistrements. Des variations d'échelle selon les attributs sont autant de perturbations possibles pour ces algorithmes. Des échelles très << étirées >> vont artificiellement rendre des dimensions trop << vides >>.
C'est typiquement le cas pour le champ Revenus dans notre exemple. Les centaines de francs ne sont pas significatives ici. Nous convertissons donc les revenus en les divisant par mille. L'intervalle de valeurs est alors dans la même échelle que les dates de naissance et les durées d'abonnement.
2.5 Fouille
La fouille de données est le coeur du processus car elle permet d'extraire de l'information des données. Néanmoins, c'est souvent une étape difficile à mettre en oeuvre, coûteuse et dont les résultats doivent être interprétés et relativisés. Il faut aussi noter qu'en situation réelle, pour l'aide à la décision, une très grande majorité des résultats recherchés s'obtient uniquement par requêtes, par analyse multi-dimensionnelle ou grâce aux outils de visualisation.
Une approche traditionnelle pour découvrir ou expliquer un phénomène est de
1. regarder, explorer,
2. établir un modèle ou une hypothèse,
3. essayer de le contredire ou le vérifier comme en 1 ; recommencer le point 2 jusqu'à obtenir une réponse de qualité satisfaisante.
La partie 1 est traditionnellement réalisée avec des outils de reporting ou d'analyse multidimensionnelle. La partie 2 est une hypothèse émise par l'uilisateur. On peut voir les outils de fouille de données comme des procédures qui permettent de faciliter ou encore d'automatiser ce processus.
La qualité du modèle obtenu se mesure selon les critères suivants :
* Rapide à créer ;
* rapide à utiliser ;
* compréhensible pour l'utilisateur ;
* les performances sont bonnes ; Le modèle est fiable ;
* les performances ne se dégradent pas dans le temps ;
* Il évolue facilement.
Il va de soit qu'aucun modèle n'aura toutes ces qualités. Il n'existe pas de meilleure méthode de fouille. Il faudra faire des compromis selon les besoins dégagés et les caractéristiques connues des outils. Dans le chapitre 2.5 nous en présentons quelques unes avec leurs avantages et inconvénients, des indications pour mieux les choisir. Pour une utilisation optimale, une combinaison de méthodes est recommandée. On peut rapidement donner 3 catégories :
Classification, régression, prédiction
Il s'agit de trouver une classe ou une valeur selon un ensemble de descriptions. Ce sont des outils très utilisés. Les algorithmes reposent sur des arbres de décision, des réseaux de neurones, la règle de Bayes, les k plus proches voisins.
Association, sequencing
Il s'agit de trouver des similarités ou des associations. Le sequencing est le terme anglais utilisé pour préciser que l'association se fera dans le temps. Par exemple, si j'achète un couffin aujourd'hui, j'ai trois fois plus de chance dans 3 mois d'acheter un lit bébé (sequencing) ou encore Si j'achète des pâtes et de la purée de tomates, j'ai deux fois plus de chance d'acheter aussi du parmesan (association).
Segmentation
La problématique est de trouver des groupes homogènes dans une population. On utilise souvent les algorithmes des k-moyennes ou de Kohonen. La difficulté essentielle dans ce type de construction est la validation qui nécessite l'intervention d'experts humains.
2.6 Validation
Les méthodes de validation vont déprendre de la nature de la tâche et du problème considéré. Nous distinguerons deux modes de validation : statistique et par expertise.
Pour certains domaines d'application (le diagnostic médical, par exemple), il est essentiel que le modèle produit soit compréhensible. Il y a donc une première validation du modèle produit par l'expert, celle-ci peut être complétée par une validation statistique sur des bases de cas existantes.
Pour les problèmes d'apprentissage non supervisé (segmentation, association), la validation est essentiellement du ressort de l'expert. Pour la segmentation, le programme construit des groupes homogènes, un expert peut juger de la pertinence des groupes constitués. La encore, on peut combiner avec une validation statistique sur un problème précis utilisant cette segmentation. Pour la recherche des règles d'association, c'est l'expert du domaine qui jugera de la pertinence des règles, en effet, l'algorithme, s'il fournit des règles porteuses d'information, produit également des règles triviales et sans intérêt.
Pour la validation statistique, la première tâche à réaliser consiste à utiliser les méthodes de base de statistique descriptive. L'objectif est d'obtenir des informations qui permettront de juger le résultat obtenu, ou d'estimer la qualité ou les biais des données d'apprentissage.
1. Calculer les moyennes et variances des attributs.
2. Si possible, calculer la corrélation entre certains champs.
3. Déterminer la classe majoritaire dans le cas de la classification.
Pour la classification supervisée, la deuxième tâche consiste à décomposer les données en plusieurs ensembles disjoints. L'objectif est de garder des données pour estimer les erreurs des modèles ou de les comparer. Il est souvent recommandé de constituer:
* Un ensemble d'apprentissage.
* Un ensemble de test.
* Un ensemble de validation.
Au moins deux ensembles sont nécessaires : l'ensemble d'apprentissage permet de générer le modèle, l'ensemble test permet d'évaluer l'erreur réelle du modèle sur un ensemble indépendant évitant ainsi un biais d'apprentissage. Lorsqu'il s'agit de tester plusieurs modèles et de les comparer, on peut sélectionner le meilleur modèle selon ses performances sur l'ensemble test et ensuite évaluer son erreur réelle sur l'ensemble de validation.
Lorsqu'on ne dispose pas de suffisamment d'exemples on peut se permettre d'apprendre et d'estimer les erreurs avec un même ensemble par la technique de validation croisée. . La validation croisée ne construit pas de modèle utilisable mais ne sert qu'à estimer l'erreur réelle d'un modèle selon l'algorithme suivant :
Admin- Admin
- Messages : 132
Date d'inscription : 14/11/2008
Localisation : Alger -
Re: Découverte de connaissance a partir des données
Admin Lun 10 Aoû - 11:05
Chapitre 3 Fouille de données
* Généralités
* Un algorithme pour la segmentation
* Les règles d'association
* Les plus proches voisins
* Les arbres de décision
* Les réseaux de neurones
On se situe dans un environnement d'aide à la décision à partir de données. On suppose que de grandes quantités de données sont disponibles. En règle générale, ces données sont structurées et correspondent aux enregistrements d'une table ou de plusieurs tables d'une base dédiée à la décision (Infocentre ou entrepôt de données). Nous allons présenter, dans ce chapitre, les tâches, i.e. les problèmes que l'on cherche à résoudre et quelques-unes des méthodes disponibles pour résoudre ces tâches.
3.1 Généralités
Les tâches
On dispose de données structurées. Les objets sont représentés par des enregistrements (ou descriptions) qui sont constitués d'un ensemble de champs (ou attributs) prenant leurs valeurs dans un domaine. On peut mettre en évidence différentes problématiques. Les termes employés pouvant varier d'une discipline à l'autre (parfois même dans une même discipline selon le domaine d'application), nous définissons notre vocabulaire avec la description associée de la tâche.
La classification :
consiste à examiner les caractéristiques d'un objet et lui attribuer une classe, la classe est un champ particulier à valeurs discrètes. Des exemples de tâche de classification sont :
* attribuer ou non un prêt à un client,
* établir un diagnostic,
* accepter ou refuser un retrait dans un distributeur,
* attribuer un sujet principal à un article de presse, ...
L'estimation :
consiste à estimer la valeur d'un champ à partir des caractéristiques d'un objet. Le champ à estimer est un champ à valeurs continues. L'estimation peut être utilisée dans un but de classification. Il suffit d'attribuer une classe particulière pour un intervalle de valeurs du champ estimé. Des exemples de tâche d'estimation sont :
* noter un candidat à un prêt ; cette estimation peut être utilisée pour attribuer un prêt (classification), par exemple, en fixant un seuil d'attribution,
* estimer les revenus d'un client.
La prédiction :
consiste à estimer une valeur future. En général, les valeurs connues sont historisées. On cherche à prédire la valeur future d'un champ. Cette tâche est proche des précédentes. Les méthodes de classification et d'estimation peuvent être utilisées en prédiction. Des exemples de tâche de prédiction sont :
* prédire les valeurs futures d'actions,
* prédire au vu de leurs actions passées les départs de clients.
Les règles d'association (analyse du panier de la ménagère) :
consiste à déterminer les valeurs qui sont associées. L'exemple type est la détermination des articles (le poisson et le vin blanc ; la baguette et le camembert et le vin rouge, ...) qui se retrouvent ensemble sur un même ticket de supermarché. Cette tâche peut être effectuée pour identifier des opportunités de vente croisée et concevoir des groupements attractifs de produit. C'est une des tâches qui nécessite de très grands jeux de données pour être effective. Cette tâche a engendré l'exemple (l'anecdote) suivant présent dans de nombreux articles sur le data mining : dans les supermarchés américains, il a été possible de mettre en évidence des corrélations entre achat de bières et achat de couches-culottes avant le week-end ! remarque justifiée par le comportement des jeunes pères américains qui préparent leur week-end en préparant leur provision de bière pour regarder la télévision et qui font les achats pour bébé au même moment. Gag ou réalité, je n'ai jamais lu de résultats sur les actions consistant à mettre, dans les supermarchés, les bières à côté des couches-culottes !!
La segmentation :
consiste à former des groupes (clusters) homogènes à l'intérieur d'une population. Pour cette tâche, il n'y a pas de classe à expliquer ou de valeur à prédire définie a priori, il s'agit de créer des groupes homogènes dans la population (l'ensemble des enregistrements). Il appartient ensuite à un expert du domaine de déterminer l'intérêt et la signification des groupes ainsi constitués. Cette tâche est souvent effectuée avant les précédentes pour construire des groupes sur lesquels on applique des tâches de classification ou d'estimation.
Les données
Ce sont les valeurs des champs des enregistrements des tables de l'entrepôt. Ces données possèdent un type qu'il est important de préciser. En effet, la plupart des méthodes sont sensibles aux données manipulées. Par exemple, certaines méthodes sont mises en défaut par les données continues alors que d'autres peuvent être sensibles à la présence de données discrètes.
Les données discrètes
* les données binaires ou logiques : 0 ou 1 ; oui ou non ; vrai ou faux. ce sont des données telles que le sexe, être bon client, ...
* les données énumératives : ce sont des données discrètes pour lesquelles il n'existe pas d'ordre défini a priori. Par exemple : la catégorie socioprofessionnelle, la couleur, ...
* les données énumératives ordonnées : les réponses à une enquête d'opinion (1: très satisfait ; 2 : satisfait ; ...), les données issues de la discrétisation de données continues (1 : solde moyen < 2000 ; 2 : 2000 £ solde moyen < 5000 ; ...)
Les données continues
ce sont les données entières ou réelles : l'âge, le revenu moyen, ... mais aussi les données pouvant prendre un grand nombre de valeurs ordonnées.
Les dates
sont souvent problématiques car mémorisées selon des formats différents selon les systèmes et les logiciels. Pour les applications en fouille de données, il est fréquent de les transformer en données continues ou en données énumératives ordonnées. On transforme une date de naissance en âge entier ou en une variable énumérative ordonnée correspondant à des tranches d'âge.
Les données textuelles
ne sont pas considérées dans ce cours. Cependant, un texte peut, pour certaines applications, être résumé comme un n-uplet constitué du nombre d'occurrences dans le texte de mots clés d'un dictionnaire prédéfini.
Les méthodes
Nous ne présentons que certaines méthodes qui viennent compléter les outils classiques que sont : les requêtes SQL, les requêtes analyse croisée, les outils de visualisation, la statistique descriptive et l'analyse des données. Les méthodes choisies qui seront détaillées dans les sections suivantes sont :
* un algorithme pour la segmentation,
* les règles d'association,
* les plus proches voisins (raisonnement à partir de cas),
* les arbres de décision,
* les réseaux de neurones,
* les algorithmes génétiques.
La présentation ne prétend pas à l'exhaustivité. Les choix effectués sont subjectifs, quoique guidés par la disponibilité des méthodes dans les environnements de data mining standard. Des méthodes importantes ne sont pas étudiées dans ce cours. Citons les réseaux bayésiens, la programmation logique inductive et les machines à vecteurs de support (SVM for Support Vector Machine). De plus, pour les méthodes proposées dans ce cours, il existe de nombreuses variantes, non présentées, qui peuvent s'appliquer à des tâches différentes. Par exemple, nous présentons, dans la section réseaux de neurones, le perceptron et le perceptron multi couches et leurs applications en classification et estimation. Cependant, il existe d'autres modèles de réseaux de neurones bien adaptés pour la segmentation (réseaux de Kohonen par exemple) ou spécialisés pour la prédiction (réseaux récurrents). En tout état de cause, un fait important communément admis est :
Il n'existe pas de méthode supérieure à toutes les autres
Par conséquent, à tout jeu de données et tout problème correspond une ou plusieurs méthodes. Le choix se fera en fonction
* de la tâche à résoudre,
* de la nature et de la disponibilité des données,
* des connaissances et des compétences disponibles,
* de la finalité du modèle construit. Pour cela, les critères suivants sont importants : complexité de la construction du modèle, complexité de son utilisation, ses performances, sa pérennité, et, plus généralement,
* de l'environnement de l'entreprise.
Nous nous attachons dans la présentation des différentes méthodes à préciser les particularités de chacune des méthodes selon ces axes.
* Généralités
* Un algorithme pour la segmentation
* Les règles d'association
* Les plus proches voisins
* Les arbres de décision
* Les réseaux de neurones
On se situe dans un environnement d'aide à la décision à partir de données. On suppose que de grandes quantités de données sont disponibles. En règle générale, ces données sont structurées et correspondent aux enregistrements d'une table ou de plusieurs tables d'une base dédiée à la décision (Infocentre ou entrepôt de données). Nous allons présenter, dans ce chapitre, les tâches, i.e. les problèmes que l'on cherche à résoudre et quelques-unes des méthodes disponibles pour résoudre ces tâches.
3.1 Généralités
Les tâches
On dispose de données structurées. Les objets sont représentés par des enregistrements (ou descriptions) qui sont constitués d'un ensemble de champs (ou attributs) prenant leurs valeurs dans un domaine. On peut mettre en évidence différentes problématiques. Les termes employés pouvant varier d'une discipline à l'autre (parfois même dans une même discipline selon le domaine d'application), nous définissons notre vocabulaire avec la description associée de la tâche.
La classification :
consiste à examiner les caractéristiques d'un objet et lui attribuer une classe, la classe est un champ particulier à valeurs discrètes. Des exemples de tâche de classification sont :
* attribuer ou non un prêt à un client,
* établir un diagnostic,
* accepter ou refuser un retrait dans un distributeur,
* attribuer un sujet principal à un article de presse, ...
L'estimation :
consiste à estimer la valeur d'un champ à partir des caractéristiques d'un objet. Le champ à estimer est un champ à valeurs continues. L'estimation peut être utilisée dans un but de classification. Il suffit d'attribuer une classe particulière pour un intervalle de valeurs du champ estimé. Des exemples de tâche d'estimation sont :
* noter un candidat à un prêt ; cette estimation peut être utilisée pour attribuer un prêt (classification), par exemple, en fixant un seuil d'attribution,
* estimer les revenus d'un client.
La prédiction :
consiste à estimer une valeur future. En général, les valeurs connues sont historisées. On cherche à prédire la valeur future d'un champ. Cette tâche est proche des précédentes. Les méthodes de classification et d'estimation peuvent être utilisées en prédiction. Des exemples de tâche de prédiction sont :
* prédire les valeurs futures d'actions,
* prédire au vu de leurs actions passées les départs de clients.
Les règles d'association (analyse du panier de la ménagère) :
consiste à déterminer les valeurs qui sont associées. L'exemple type est la détermination des articles (le poisson et le vin blanc ; la baguette et le camembert et le vin rouge, ...) qui se retrouvent ensemble sur un même ticket de supermarché. Cette tâche peut être effectuée pour identifier des opportunités de vente croisée et concevoir des groupements attractifs de produit. C'est une des tâches qui nécessite de très grands jeux de données pour être effective. Cette tâche a engendré l'exemple (l'anecdote) suivant présent dans de nombreux articles sur le data mining : dans les supermarchés américains, il a été possible de mettre en évidence des corrélations entre achat de bières et achat de couches-culottes avant le week-end ! remarque justifiée par le comportement des jeunes pères américains qui préparent leur week-end en préparant leur provision de bière pour regarder la télévision et qui font les achats pour bébé au même moment. Gag ou réalité, je n'ai jamais lu de résultats sur les actions consistant à mettre, dans les supermarchés, les bières à côté des couches-culottes !!
La segmentation :
consiste à former des groupes (clusters) homogènes à l'intérieur d'une population. Pour cette tâche, il n'y a pas de classe à expliquer ou de valeur à prédire définie a priori, il s'agit de créer des groupes homogènes dans la population (l'ensemble des enregistrements). Il appartient ensuite à un expert du domaine de déterminer l'intérêt et la signification des groupes ainsi constitués. Cette tâche est souvent effectuée avant les précédentes pour construire des groupes sur lesquels on applique des tâches de classification ou d'estimation.
Les données
Ce sont les valeurs des champs des enregistrements des tables de l'entrepôt. Ces données possèdent un type qu'il est important de préciser. En effet, la plupart des méthodes sont sensibles aux données manipulées. Par exemple, certaines méthodes sont mises en défaut par les données continues alors que d'autres peuvent être sensibles à la présence de données discrètes.
Les données discrètes
* les données binaires ou logiques : 0 ou 1 ; oui ou non ; vrai ou faux. ce sont des données telles que le sexe, être bon client, ...
* les données énumératives : ce sont des données discrètes pour lesquelles il n'existe pas d'ordre défini a priori. Par exemple : la catégorie socioprofessionnelle, la couleur, ...
* les données énumératives ordonnées : les réponses à une enquête d'opinion (1: très satisfait ; 2 : satisfait ; ...), les données issues de la discrétisation de données continues (1 : solde moyen < 2000 ; 2 : 2000 £ solde moyen < 5000 ; ...)
Les données continues
ce sont les données entières ou réelles : l'âge, le revenu moyen, ... mais aussi les données pouvant prendre un grand nombre de valeurs ordonnées.
Les dates
sont souvent problématiques car mémorisées selon des formats différents selon les systèmes et les logiciels. Pour les applications en fouille de données, il est fréquent de les transformer en données continues ou en données énumératives ordonnées. On transforme une date de naissance en âge entier ou en une variable énumérative ordonnée correspondant à des tranches d'âge.
Les données textuelles
ne sont pas considérées dans ce cours. Cependant, un texte peut, pour certaines applications, être résumé comme un n-uplet constitué du nombre d'occurrences dans le texte de mots clés d'un dictionnaire prédéfini.
Les méthodes
Nous ne présentons que certaines méthodes qui viennent compléter les outils classiques que sont : les requêtes SQL, les requêtes analyse croisée, les outils de visualisation, la statistique descriptive et l'analyse des données. Les méthodes choisies qui seront détaillées dans les sections suivantes sont :
* un algorithme pour la segmentation,
* les règles d'association,
* les plus proches voisins (raisonnement à partir de cas),
* les arbres de décision,
* les réseaux de neurones,
* les algorithmes génétiques.
La présentation ne prétend pas à l'exhaustivité. Les choix effectués sont subjectifs, quoique guidés par la disponibilité des méthodes dans les environnements de data mining standard. Des méthodes importantes ne sont pas étudiées dans ce cours. Citons les réseaux bayésiens, la programmation logique inductive et les machines à vecteurs de support (SVM for Support Vector Machine). De plus, pour les méthodes proposées dans ce cours, il existe de nombreuses variantes, non présentées, qui peuvent s'appliquer à des tâches différentes. Par exemple, nous présentons, dans la section réseaux de neurones, le perceptron et le perceptron multi couches et leurs applications en classification et estimation. Cependant, il existe d'autres modèles de réseaux de neurones bien adaptés pour la segmentation (réseaux de Kohonen par exemple) ou spécialisés pour la prédiction (réseaux récurrents). En tout état de cause, un fait important communément admis est :
Il n'existe pas de méthode supérieure à toutes les autres
Par conséquent, à tout jeu de données et tout problème correspond une ou plusieurs méthodes. Le choix se fera en fonction
* de la tâche à résoudre,
* de la nature et de la disponibilité des données,
* des connaissances et des compétences disponibles,
* de la finalité du modèle construit. Pour cela, les critères suivants sont importants : complexité de la construction du modèle, complexité de son utilisation, ses performances, sa pérennité, et, plus généralement,
* de l'environnement de l'entreprise.
Nous nous attachons dans la présentation des différentes méthodes à préciser les particularités de chacune des méthodes selon ces axes.
Admin- Admin
- Messages : 132
Date d'inscription : 14/11/2008
Localisation : Alger -
Page 1 sur 1
Permission de ce forum:
Vous ne pouvez pas répondre aux sujets dans ce forum|
|
|